



ロードマップでわかる!当世プロセッサー事情 第673回
インテルがAIプロセッサーに関する論文でIntel 4の開発が順調であることを強調 AIプロセッサーの昨今
2022年06月27日 12時00分更新

命令実行段に手を入れる必要がないので
RISC-Vを利用するのは非常に理に適った選択
試作チップにRISC-Vを使った理由だが、それは実装しやすいからである。今回ベースとしたのは、CVA6である。もともとはArianeという名前で、System Verilogというハードウェア記述言語で構築されたインオーダー、6段パイプラインの比較的シンプルな、ただし64bit RISC-VでLinuxも動作するという使いやすいコアである。
ただこのArianeはOpenHWに移管され、CVA6という名称に変更された。現在のCVA6の構成は下の画像のとおりで、命令実行段(EX)のみOut-of-Order Writebackが可能になっている仕組みだ。
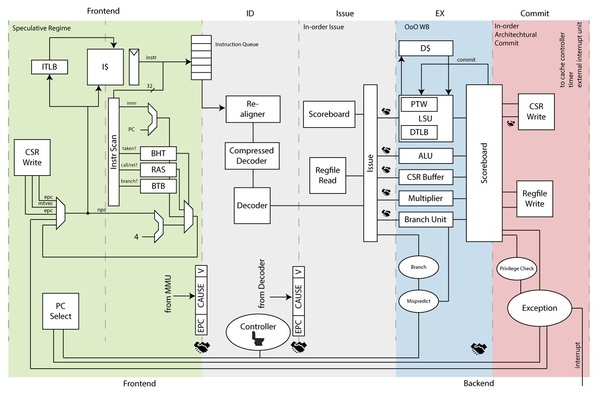
フロントエンド2段、IDとIssue、Ex、Commitが各1段という構成。一応Issueからは最大5命令同時発行になっているが、そもそもInstruction Queueからは1命令/サイクルでの取り込みなので、実質In-Orderとしても差し支えない
現状ではOut-of-Orderといっても実質1 RISC-V命令/サイクルでの処理しかできないのだが、もともとRISC-V命令が「複雑なISAを搭載するよりも、複雑なものはどうせ内部分解して複数命令で処理するのだから、ISAそのものは単純に留めよう」という発想になっているので、内部処理で言えば2命令/サイクル程度で動くこともあるかもしれない。
それはともかく。今回の改造では、命令実行段そのものには手を入れる必要がない。ただしCNCを動かす関係で、命令デコーダにCNC用の命令を追加するとともに、CNCを実行する際にCNCが参照するLLCのエリアに割り当てられているメモリーの物理アドレス(Sv39 address)を通知し、またIssueポートにCNCに対してコマンドを発行するユニットを追加する必要がある。
こうした改造を行なうのに、x86では内部構造が複雑すぎる。もちろんGNAと同じようにP54コアを使うという案もあるのだが、これだともともとのコアの性能が低すぎて、CNCを入れても評価の妨げになりそうである。
一方でArmコアを使うと、こんな調子で勝手に命令デコードに手を入れられない。ところがRISC-Vの場合、そもそもカスタム命令の追加も自由にできるし、今回のCVA6のように変更のベースとするのに使い勝手の良いコアが無償で配布されている。そのままの製品化を考えないのであれば、RISC-Vを利用するのは非常に理に適った選択だ。
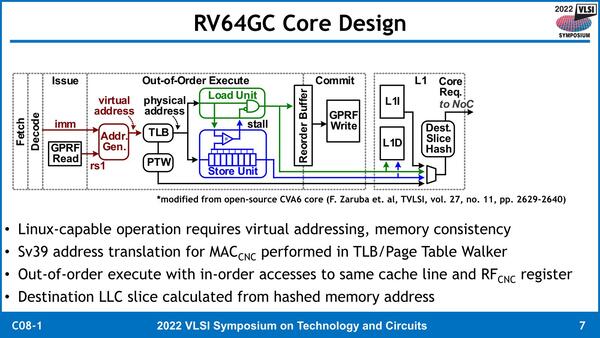
黒い部分がもともとのCVA6のままで、色付きの部分が手を入れた場所である
一方のLLC側の変更点が下の画像だ。タグや状態管理、コヒーレントやキャッシュHit/Miss管理、ディレクトリなどは別にCNCがあってもなくても必要なモノであり、追加するのはCNCそのものと、SRAMとCNCのI/F、それとCNCとコアのレジスターの間のI/Fだけである。
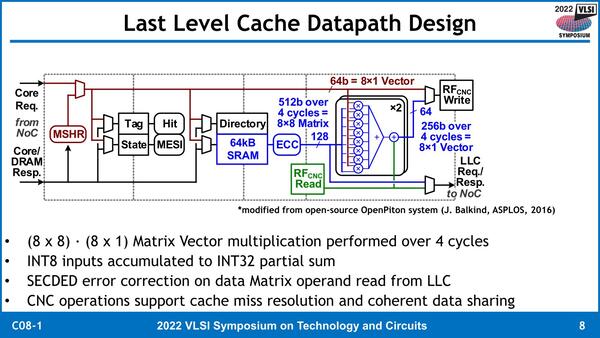
LLC側の変更点。SECDED(Single Error Collection/Double Error Detection:1bitエラー修正、2bitエラー検出)機能は、ECCとして搭載される部分のこと
改造に必要なものが最小限で済み、それでいて基本的なRISC-Vのコアそのものには手を入れていないから、CNCを使わなければただのCVA6コアとして動くので、RISC-V向けのソフトウェアがそのまま利用できるというのも手間がかからない部分である。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ



















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")


































