



ロードマップでわかる!当世プロセッサー事情 第673回
インテルがAIプロセッサーに関する論文でIntel 4の開発が順調であることを強調 AIプロセッサーの昨今
2022年06月27日 12時00分更新

汎用品と比べて性能は260倍、エネルギー効率は35倍
おそろしく効率の良い演算が可能
今回インテルはIntel 4プロセスを使ってこのプロセッサーを製造している。CNCを追加したことによるオーバーヘッドはエリアサイズの1.4%増加程度に留められている。プログラムはほとんどの部分がRISC-V用のコンパイラを使ってC++で記述され、今回追加したCNC向けはインラインアセンブラで記述、というやり方で試したそうだ。
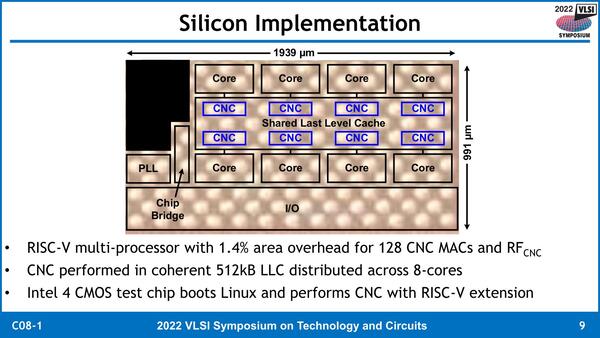
ダイサイズはわずかに1.92平方mm。これで1GHz動作するのだからたいしたものである

左のソースの中で、CNMWR()やCNMMAC()、CNMRF()がそのインラインアセンブラの部分と思われる。gccの変更版というのは、おそらくCNC用の追加命令をサポートするようにしたのだろう
下の画像は電圧と動作周波数および消費電力をまとめたものである。青い方は電圧-動作周波数の関係で、0.55Vで350MHz、0.75Vで1.15GHz動作となっている。
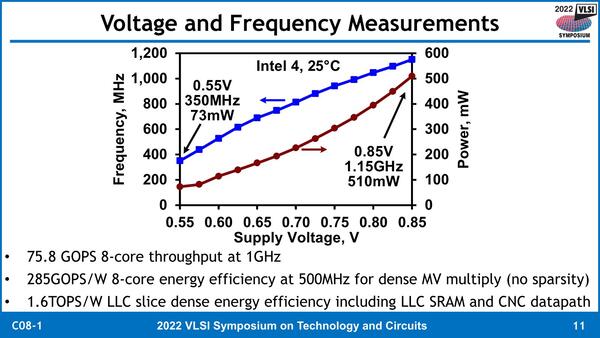
電圧と動作周波数、消費電力をまとめたもの。もっともこのスライドは、CNCというよりもIntel 4をアピールする目的が強いように思われる
CVA6のような単純な(つまりパイプライン1段あたりの処理が大きく、動作周波数を上げやすい)コアでも0.85Vで1.15GHz動作するという話であり、その際の消費電力は0.55Vでわずか73mW、0.85Vでも510mWでしかない。
一方で性能の方は、8コアを1GHzで動かしたときに75.8GOPSほど。1GHzでは消費電力は400mW程度なので、性能は189.5GOPS/Wほどになる。500MHzまで落とすと285GOPS/W、LLCだけの消費電力で言えば1.6TOPS/Wという、おそろしく効率の良い演算が可能になる、とされた。
さて上で説明したように、CNCは汎用というよりはもう明確に畳み込み演算に特化した構造になっているわけで、当然ながらAIというか畳み込みニューラルネットワークでの処理性能が重要になってくる。これに関して、CVA6の内蔵エンジン(スカラー:赤)と、CNC(青)を利用した場合の性能を、全結合層と畳み込み層で比較したのが下の画像である。
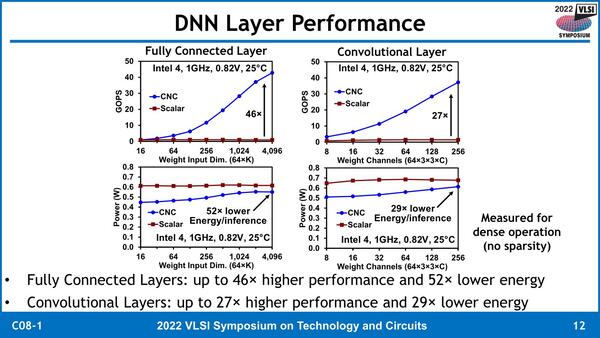
CVA6にこうした処理をさせるのがそもそも間違っているという気はするのだが、とりあえず比較したいという気持ちはわかる
スカラーを使うと、とにかく性能が低いというか全然話にならないし、ウェイトデータの次元数やウェイトのチャネルが増えても全然性能が上がらないが、CNCではどんどん性能が改善し、しかも消費電力そのものはスカラーより低めだから、エネルギー効率は52倍や29倍という話になる。
もう少し現実的な比較としては、MLPerfのTiny Anomaly Detectionを実施してみた結果がこちら。This Workというのが今回のもので、他のNucleoやRaspberry Piなどは、すでにMLPerfに登録されている結果である。
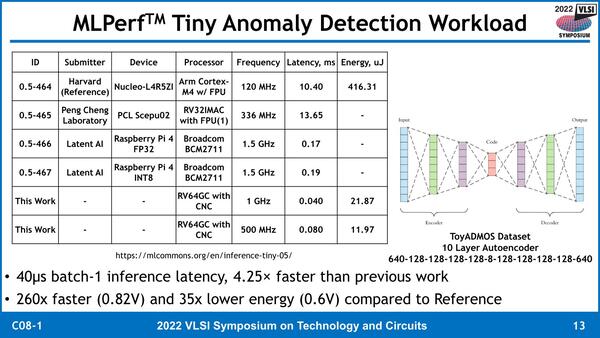
2つ目のPeng Cheng Laboratoryは32bit RISC-Vコアを使ったものだが、ボードの詳細が不明である。ひょっとしてFPGAかなにかで実装してテストした結果なのかもしれない(消費電力が示されていないあたりがいかにもそれらしい)
ただこれも、汎用のRaspberry Pi 4を使ったとか、一番上のNucleo-L4R5ZIに至ってはSTMicroelectronicsの出している開発ボードであるSTM32 Nucleo-144を使ったものなので、性能比較の対象としてどうだろう? という気はするのだが、とりあえずこうした汎用品と比べてレイテンシーは4分の1未満であり、性能は260倍、エネルギー効率は35倍にもなる、という説明であった。
インテルがこれを直近の製品に投入する可能性は少ない。Meteor LakeはMyriad Xないしその次期製品を統合するらしいという話は連載657回で説明したが、実際に統合されるのは第3世代のVPU(つまりMyriad Xの次の世代のもの)になるとのことだ。
ついでに言えばこの第3世代のVPUは単体カードでの提供の予定はなくなり、Movidiusのチームは全部CCG(Client Computing Group)に移籍したとかで、今後はCoreプロセッサーの中のアクセラレーターとして提供されることになる。したがって、直近はこのMovidius由来のものが使われることになるだろう。ただ長期的には、PIMというかCNCというか、そうしたモデルがAI向けにはけっこう有用ということが今回の論文で示された格好だ。
ちなみにこの論文の影の役割は、「Intel 4が確実に来そう、と人々に信じさせること」である。今回RISC-VコアをIntel 4で製造して見せたというのは、IFS(Intel Foundry Service)がRISC-V Internationalに加盟してRISC-Vコアの製造をサポートし、またIFSの最初の汎用ロジック向けがIntel 3であることを考えると、「この通り作れます」というアピールになるわけだ。
冒頭でIntelがVLSI Symposiumで論文を12本を出した、という話をしたが、このうち以下の5本がIntel 4に絡めたものになっている。
| VLSI Symposium 2022で発表されたIntel 4に関する論文 | ||||||
|---|---|---|---|---|---|---|
| T01-1 | Intel 4 CMOS Technology Featuring Advanced FinFET Transistors optimized for High Density and High Performance Computing | |||||
| C08-1 | An 8-core RISC-V Processor with Compute near Last Level Cache in Intel 4 CMOS | |||||
| C13-3 | A 90.9kS/s, 0.7nJ/conversion Hybrid Temperature Sensor in 4nm-class CMOS | |||||
| C16-1 | A 7Gbps SCA-Resistant Multiplicative-Masked AES Engine in Intel 4 CMOS | |||||
| C24-1 | Energy-Efficient High Bandwidth 6T SRAM Design on Intel 4 CMOS Technology | |||||
冒頭のT01-1はそのものズバリIntel 4の詳細だが、それ以外にIntel 4を利用した回路の論文を4つも出すあたり、インテルとしてはこんな形でIntel 4が順調であることを強調する必要性がある、というあたりが逆にIntel 4に不安を感じさせる。筆者の勘繰り過ぎだと良いのだが。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ











、バッテリー駆動時間は13時間超え。もう欲しくなる要素しか見つからないッ!")








ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")
















