




ディープラーニングに振り切ったAiMの内部構造
内部構造であるが、16個のDRAMバンクに16個のPU(Processing Unit)が分散される形で実装され、それとは別に2KBのグローバル・バッファが中央に置かれる格好になっている。
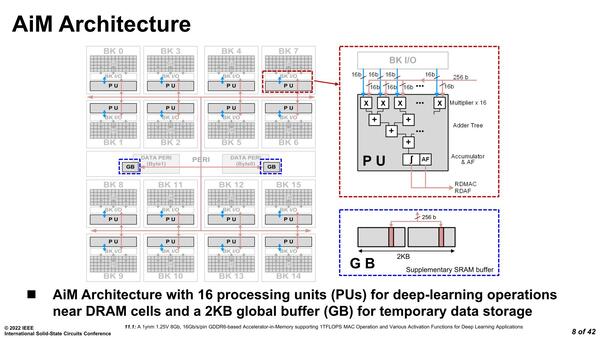
GBが置かれるのは通常ではRaw Decoderなどが置かれる場所となる
そのPUであるが、最大16個のデータのMAC演算が可能である。データ型はBF16なので、DRAMバンクから256bit分のデータを一気に読み出し、これをそのまままず乗算を行ない、その結果を加算して、最終的にアクティベーションするところまでを完全にパイプライン化している。
ところで前回も書いたが、MAC演算とはY=A×X+Bという処理になる。ここでXが入力値、Aがウエイト、Bがオフセットで処理結果がYである。ウエイトにあたるA(と必要ならオフセットのB)はDRAMから取ってくるわけだが、入力にあたるXをどこから持ってくるのか? というと、パターンが2つある。
1つはグローバル・バッファを利用する方法である。もう1つは複数のバンクからそれぞれデータを取る方法だ。大きな入力に対して、単一のウエイトを適用するようなシーンではこちらが利用できることになる。
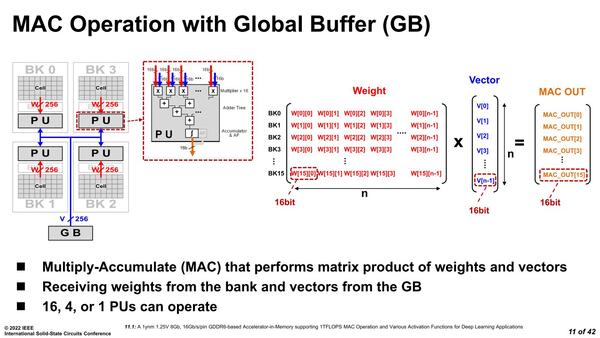
GBを利用する方法。入力に対してさまざまなウエイトをかけて、その結果を組み合わせる場合にはこの方法が有効だ
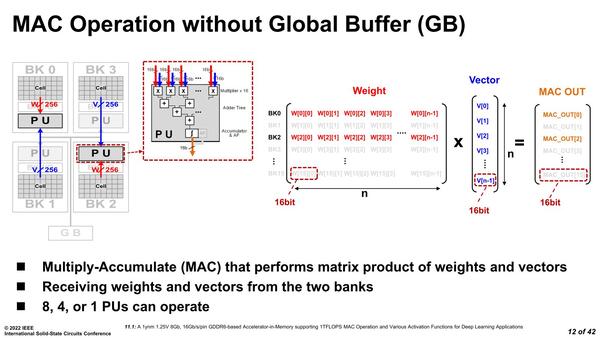
複数のバンクからそれぞれデータを取る方法。この場合2バンクが連携して動作することになり、PUが半分休止になるわけだ
それぞれのPUで行なえる処理が下の画像だ。そのバンクを有効にする/しない、MAC演算、活性化、乗算のみ(MAC演算はしない)といった処理命令と、後はデータの移動に関わるものだけである。
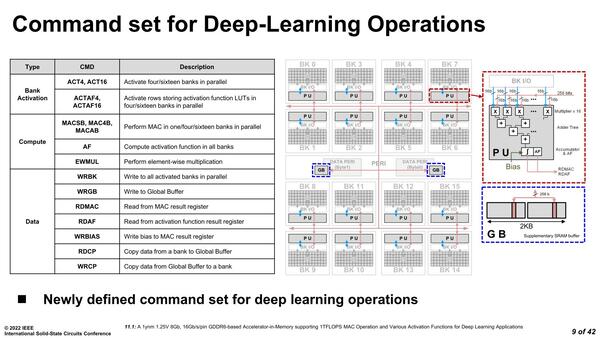
EWMULは乗算の後の加算を動かさず、乗算の結果をそのまま出力するものとなる
DRAMセル混在ということもあり、あまり複雑な命令はサポートしていないし、BF16というデータフォーマットの時点で科学技術計算などにはかなり厳しい(なにしろ仮数部が7bitしかないから、実質2桁精度)わけで、もう完全にディープラーニングに振り切った構成になっているのはいっそ潔いというべきか。
MAC演算の基本的な仕組みが下の画像である。16個の乗算器の出力(ここに一応出力制御とShifterが入っている)を、15個の乗算器でツリー状に加算していく形態である。
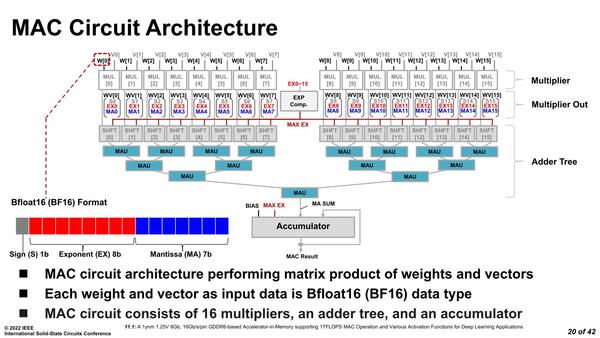
これが1つのPU内に収められている
ちなみにこの加算器のツリーは4層になっている関係で、普通に処理をすると加算に4サイクルかかる計算である。乗算まで加えると5サイクルで実施できることになる。
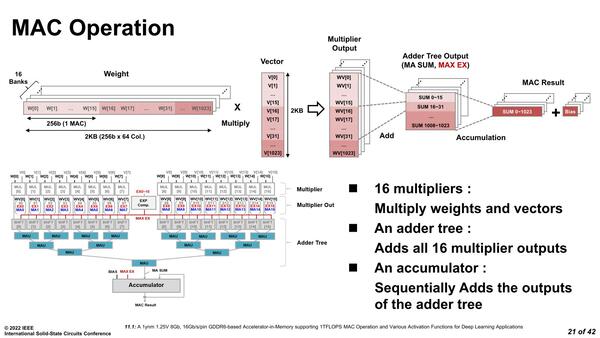
レイテンシーが5サイクルという話で、スループットそのものは1サイクルである
これをもう少し高速化したい、ということでSK Hynixが提案しているのはBWMS(Bank-Wide MA Shift)である。整数の加算であれば話は簡単なのだが、BF16の場合は浮動小数点なので、指数部(Exponent)と仮数部(Mantissa)を別々に扱う必要がある。
例えば100+10、という計算は整数型なら計算一発である。ところが浮動小数点だとそれぞれ1.0×102+1.0×101、と表現されることになる。したがって、まず最初に指数部の桁をそろえる必要があり、10.0×101+1.0×101か、1.0×102+0.1×102と変換(どちらにするかは処理系の実装次第)してから加算する必要がある。
これをツリー上の加算で毎回やってるから処理が増えることになる。そこで、1バンク16個分のデータについて、最初に指数部を統一してしまえば、あとは符号付7bitの加算だけで済むので、処理時間を大幅に減らせる、というものだ。これは単に性能だけでなく消費電力やエリアサイズの削減にもつながる、としている。
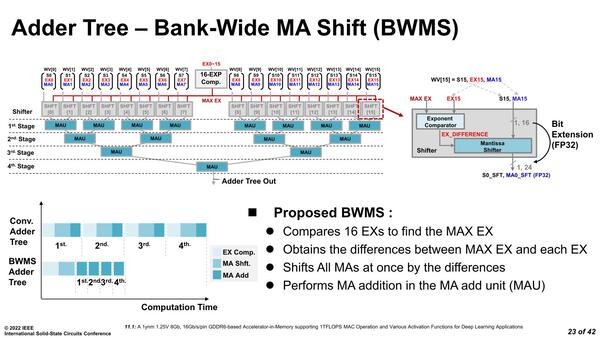
最初に指数部を統一してしまえば加算部のレイテンシーを2サイクルまで減らせるとする
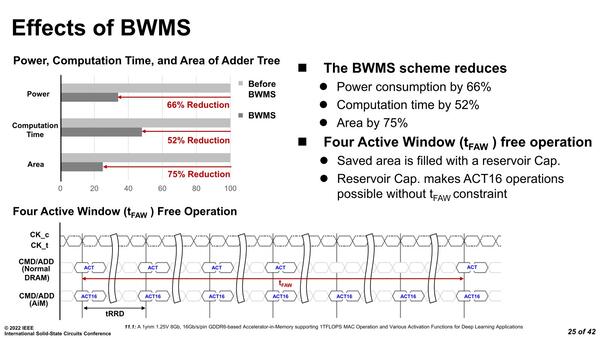
加算の高速化により、CMD/ADD(コマンド/アドレス)と同じタイミングで処理が可能になる、としている。もともとGDDR6の場合、CMD/ADDはデータ転送レートの1/4の速度で伝送されており、これにあわせて結果を出力できるようになるわけだ
ちなみにPUに対する処理は、CMD/ADDラインを使って送る形で実装されているようで、このあたりはHBM-PIMと発想は同じである。
いまさら信号線を増やすわけにもいかないし、そもそもこの方式の場合はまずDRAMセルにデータを埋め(これは通常のデータ書き込み)、ついでPUに対して処理を行ない(ここが拡張部分)、最後に結果を受け取る(これは通常のデータ読み込み)という形になるから、PUの制御I/Fを別に用意するよりも、既存のCMD/ADD経由の命令を拡張する方が賢明だろう。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ











の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")





























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






















