




久しぶりに今週はNVIDIAの話だ。前回のロードマップアップデートが連載581回なので半年ぶりである。なぜこんなに空いたかと言えば、新製品がまったく出てこないのが理由である。今年1月に発表になったGeForce RTX 3080 12GBは新製品と言えば新製品だが、基本的にはGeForce RTX 3080 Tiのダウングレード版ということを考えると、バリエーションチェンジの範疇と言えよう。
そんなNVIDIAであるが、3月23日からオンライン開催となったGTC 2022の基調講演で、次世代GPUであるHopperが発表になった。実際にはHopperだけでなく、ものすごく盛り沢山の発表があり、これを全部カバーするのは1本の記事では到底不可能なのだが、現状ではまだ詳細が明らかにされないGraceなどは後回しにして、一番の目玉とでもいうべきHopperことNVIDIA H100 GPUについて今回は説明しよう。

HopperことNVIDIA H100
NVIDIAが次世代GPUの“Hopper”こと「GH100」を発表
まずはJensen Huang CEOの基調講演から、Hopperに話を絞って説明しよう。Hopperというコード名で開発されたGH100は、HBM3を6つ搭載するやはりお化けチップであった。

「次世代のAIプロセッサーを紹介する」と言うCEOの脇から柱がせり出し、GH100チップが湧いてきた

長辺にHBM3が3つづつ並んでいるあたりでチップそのものの大きさがわかろうというもの
性能はFP32/FP64で60TFlops、AI向けのFP8では4000TFlopsに達する(FP8の話は後述)。TSMCのN4をベースとした、カスタム版の4Nプロセスで製造され、トランジスタ数は800億個に達する。ちなみにダイサイズは814mm2で、おそらくEUVステッパーのReticle Limit(露光できる寸法の限界)ギリギリなのだと思われる。
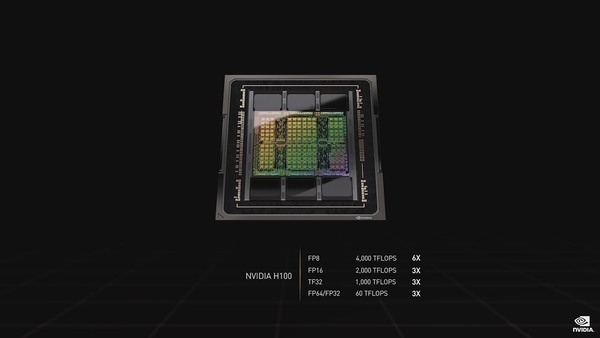
もう素直にTF32で1PFlops、FP8では4PFlopsと書いた方が良かったような気がする

Bandwidthの話は後述する

4nm世代で800平方mmオーバーなのは、現時点では間違いなく"World's Most advanced Chip"である
またこのスライドではNVIDIA H100となっているが、正式にはチップの名称がGH100、これを搭載したモジュールがH100である(わりとこのあたりがNVIDIAの資料を見ているといい加減なのがアレだが)。
新機能として挙げられているのはTransformer Engine、第2世代のMulti-Instance、Confidential Computing、第4世代NVILink、DPX命令セットなどであるが、これはこの後もう少し詳細な説明があるのでそちらで説明したい。
このGH100を搭載したSXMモジュールであるH100は1個あたり700Wの消費電力とされる。このH100を8つ搭載したのがHGX H100となる。そのHGX H100にCPUやNetwork、Storageなどを追加したのがDGX H100である。

Radeon Instinct MI250で採用されたOAMと似たサイズであるが、Radeon Instinct MI250は2ダイで700W。一方こちらは1ダイで700Wである。いろいろな意味ですさまじい

性能の横の6Xや3Xは、AmpereベースのHGX A100との比較である

上の画像では黒いカバーがかかっているが、その下にはこんなクーラーが搭載されているそうだ

演算性能そのものはHGXもDGXも変わらない。これは別にHopperだけでなく以前もそうである
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 -
第873回
PC
「銅配線はまだ重要か? 答えはYesだ」 NVIDIA CEOジェンスンが語った2028年ロードマップとNVLink 8の衝撃 - この連載の一覧へ






































ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












