




Sapphire Rapidsはダイ同士の接続に独自方式を採用
ダイをまたいだ通信の遅さを解決している
クライアント向けはこの程度にして、次はサーバー向けについて説明しよう。長年発表だけがあったSapphire Rapidsが、今年中にリリースされるのは当然(万一これが延期するといろいろなものが本当にヤバくなる)として、その次にEmerald Rapids/Granite Rapidsと続くのと併せ、2024年にはSierra Forestが投入され、さらにその次も予定されていることが今回明らかになった。

Sapphire Rapidsの後継となるEmerald Rapidsも引き続きIntel 3のまま。そしてGranite RapidsはIntel 3での製造になる
連載598回の最後で説明したが、少なくとも2020年末の段階では、E-CoreというかAtomベース「のみ」のディスクリート製品はなくなる予定だった。ところがその後E-Coreは奇跡の復活(?)を見せている。
まずChromebookや組み込み向けに、Alder Lake-Nが用意されるらしい。これはP-Core×0/E-Core×8という構成になるそうだ。これがあるということは、ひょっとするとRaptor Lake世代でもRaptor Lake-Nが出てくるかもしれない。そしてXeon向けには2024年にN-CoreのみのSierra Forestが発表された。
このSierra Forestの目的は比較的明快である。AMDのZen 4c対抗というか、根っこで言えばArmのNeoverse N2対抗である。要するにクラウドなどのスケールアウト用途向けにP-Coreではオーバースペック過ぎるという話で、ここに向けてE-Coreベースの製品を投入するという話である。
さて、Xeonの製品ロードマップとしては以上であり、これ以上詳細は語られていない(強いて言えば下の画像程度である)が、実は今年のISSCCでそのSapphire Rapidsの詳細が公開されたので、解説したい。

Nvidia A100比で2倍とあるが、「ワークロードと構成はこちら」のページの先が404というオチまでつけてなにをしたいのか……
まず基本構成であるが、実は昨年10月のLinley Fall Processor Conferenceの折に、Sapphire Rapidsは鏡対称を成す2種類のタイルで構成される、という話をインテルの担当者に確認している。つまり4つのタイルは下の画像のように2種類のタイルで構成されるわけだ。

黄色と水色の2種類のタイルを各々2つづつで合計4つとなる
さて、問題はこのダイの接続方法である。連載631回で推定した時はUPIベースでの接続かと思ったのだが、UPIはパッケージ間接続用に残されているものの、ダイ同士の接続は独自のMDF(Multi-Die Fabric IO)と呼ばれる方式を使うという話であった。
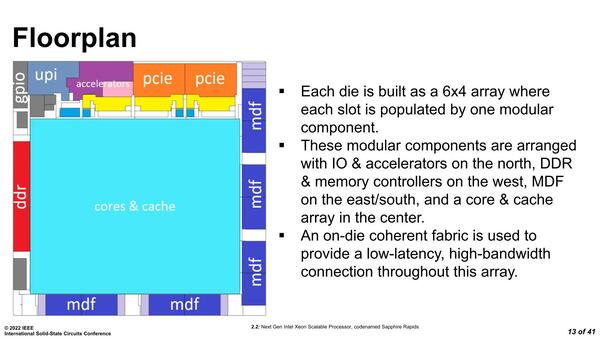
MDFが結構多いあたり、実はタイル間がかなり密に結合されていることがわかる
接続方法そのものはEMIBで、全部で10個EMIBを利用しているという話であったが、その接続方法が下の画像だ。
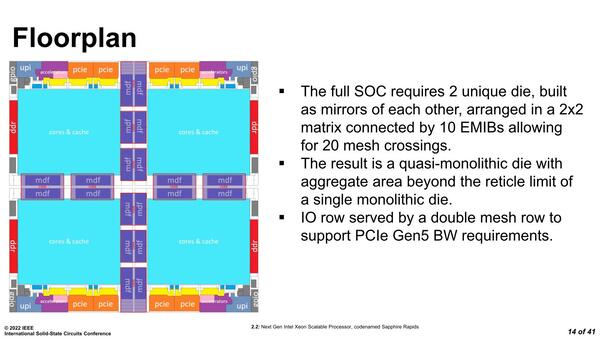
なるほどこれならトータルで10個のEMIBになるわけだ。斜め方向の配線は省いたのは賢明かもしれない
ちなみにMDFのバス幅は未公開ながら、1対の信号速度は0.8~5GT/秒(DVFSで動的に可変できるらしい)。PCI Expressなどと異なりクロック信号は別に供給される、要するにパラレルバス形式になっており、タイルあたりの平均転送速度は500GB/秒、タイル間のレイテンシーは2.4nsと説明されている。タイルには合計で5つのMDFを持ち、送受信合わせて500GB/秒とすると、MDFあたり100GB/秒。信号速度が5GT/秒ということは、MDFは10対20本の信号線から構成されるものと思われる。
まだ性能などの詳細は未公開であるが、とりあえずEPYCやThreadripperなどで問題とされた「ダイをまたいだ通信の遅さ」は、Sapphire Rapidsでは徹底的に対策されているようだ(それでも同じタイルの中をアクセスする場合と比べたら遅いとは思うが)。
次にSapphire Rapids HBM(High Bandwidth Memory)の話であるが、実はこの製品はDGAI(Data Center and AI Group:旧DCG)ではなく、今回新設されたAXG(Accelerated Computing Systems and Graphics Group)の管轄になることがわかった。このAXGのトップはおなじみRaja Koduri氏で、グラフィックスとHPC向けの製品を扱う。つまりSapphire Rapids HBMは一般のサーバー向けではなく、HPC向けとなるわけだ。

この“Sampling Today”というのは、遅延を重ねたAurora向けの出荷がスタートした、ということだろう
そのAXGのロードマップが下の画像である。2023年にはXeon Next HBM(Emerald Rapids HBMなのか、Granite Rapids HBMなのかは判断できない)とPonte Vecchio Nextをさらに投入するとしている。

クライアント向けGPUは、今年中にAlchemistベースの製品が出るが、次は2023~2024年の期間ということがわかる
またMedia/Analytics向けにArctic Soundという製品が投入とあるが、こちらはInvestor Meetingが行なわれた2月17日にサンプル出荷開始が発表された。

クラウドゲーミングとビデオトランスコードに主眼を置いた製品。2020年11月に発表されたIntel Server GPUの後継である
またディスクリートGPUについてはノート向けはすでにAlderLake-Hなど向けに出荷が公表されているが、第2四半期中にデスクトップ向け、第3四半期中にワークステーション向けが用意されるという以上の話はなかった。
おそらくワークステーション向けは、ハードウェア的にはデスクトップ向けと大差なく、ただしアプリケーションの認証を取得したドライバーが付属するという形のものになるだろう
ということで、今年この後投入される製品は以下のようになる。
~3月末 :Sapphire Rapidsベースの第4世代Xeon Scalable(と、おそらくXeon-W)
~6月末 :Alchemist DG2
~9月末?:Raptor Lake
もともとSapphire Rapidsは、昨年8月のArchitecture Dayの折には2022年初頭に投入という説明があったと記憶しているが、すでに3月に突入している状況で初頭もへったくりもないわけで、まずはこれが無事にリリースされることを祈りたいところだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第870回
PC
スマホCPUの王者が挑む「脱・裏方」宣言。Arm初の自社販売チップAGI CPUは世界をどう変えるか? -
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 - この連載の一覧へ















の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")



























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")

















