




インテルのロードマップアップデートも一段落しており、次は10月末に開催されるIntel Innovation待ちである。実を言えば海外ではぼちぼちLGA 1700対応のマザーボードの話が出てきたりしてはいるのだが、まだ製品発表には遠そうだ。
それはともかくとして、ここにきてHPC関係の話がいろいろ出てきたので、今回はこれをまとめてご紹介しよう 。

AMDがHPCの性能効率を
2025年までに30倍にすると発表
9月29日、AMDは2025年までにHPCおよびAIワークロードの性能効率を30倍にすると発表した。これは2020年時点のプラットフォームなので第2世代EPYCと比較して、2025年のプラットフォームでは性能/消費電力比を30倍に引き上げるという話である。ちなみに組み合わせられるGPUは、Radeon Instinct MI100なのか、その前世代製品であるRadeon Instinct MI50なのかははっきりしない。
この30倍、実はAI向けに関して言えばそれほど難しくはない。そもそもEPYCにしてもRadeon InstinctにしてもAI向けという観点で言えばまだ未対応という方が正確であって、BF16へのサポートこそ追加されたもののまだ効率的にAI処理を行なうような仕組みは搭載されていない。
インテルで言えばVNNIやXe Coreに搭載されたMatrix Engineに相当する仕組みであって、これを搭載すれば現状の10倍くらいの効率を達成するのはそう難しくない。というより、現状が低すぎるというべきだろう。
これとプロセス微細化や回路の改良などを積み重ねていけば、30倍は(簡単とは言わないが)達成可能だろう。むしろ難しいのはHPC分野であって、それこそインテルのAMXに相当する大規模なMatrix Engineなどのアクセラレーターを考慮する必要がある。
現状CDNAにはインテルのXeのMatrix Engineや、NVIDIAのTensor Coreにあたるものが実装されていないので、このあたり(おそらくはNVIDIAのTensor Core Gen2に近い、FP64の行列演算が可能なもの)を実装してくる形で対応すると思われる。
さらに余談であるが、AMDがVNNIをサポートするかどうか、現状ではやや疑わしい。というのはVNNIはAI向けミドルウェアとしてはOpenVINOおよびoneAPIに事実上紐付いてしまっているからで、oneAPIはともかくOpenVINOをAMDがサポートできるか? という話になるからだ。したがって、独自実装の形でAIアクセラレーター命令を搭載し、それをROCm経由で利用できる、という形になりそうな気がする。
AMDが発表した構成がFrontierに酷似
そこからFrontierのノード構成を推定
さて、ここまでの話は単に枕である。その性能効率30倍に関してAMDのSVP兼研究員であるSam Naffziger氏の説明があったのだが、そのNaffziger氏が説明に利用したスライドの1枚が下の画像だ。左の図を拡大したのがその下の画像である。
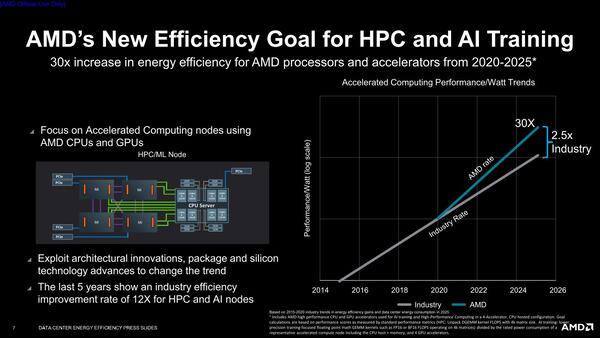
「業界標準に比べて2.5倍の改善率を達成する」という意気込みもすごい
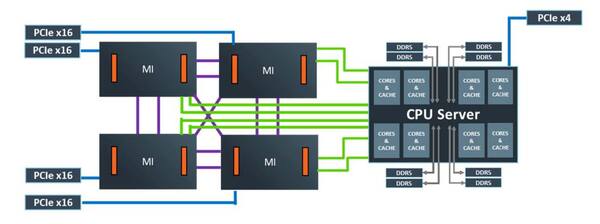
問題の構図。さてこれをどう見るべきか
これが何か? というと「単なる一例」とされそうだが、AMDとCray(現HPE)が2022年にオークリッジ国立研究所に納入するスーパーコンピューターFrontierのノードがやはり1×EPYC+4×Radeon Instinct構成になる。
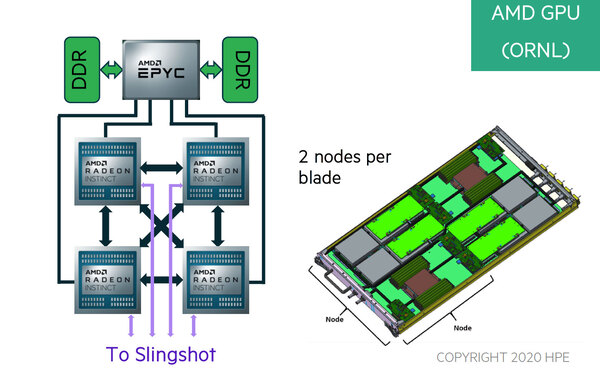
こちらはオークリッジ国立研究所のFrontierのページに掲載されている“NODE Diagram”のもの
このノードの構成が先の構図に酷似しているあたりは、どう見てもNaffziger氏の画像はFrontierの構成をベースにしていると考えざるを得ない。
これを前提に、Frontierのノード構成を推定したのが下図になる。まずEPYCはまだGenoaは間に合わないので、実際にはMilanベースになるだろう。というより、最終構成はGenoaベースになるのかもしれないが、2021年の納入時にいきなりGenoaベースはかなり無理がある。
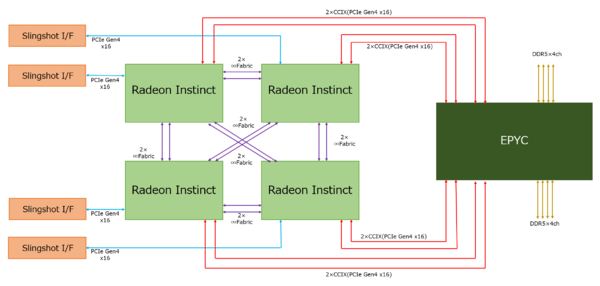
Frontierのノード構成推定図
図ではDDR5メモリーを接続する形態になっているが、これもMilanベースの当初納入時はDDR4ベースで、あとからGenoaベースに更新される際にDDR5ベースにボードごと切り替わるものと思われる。Frontierの稼働に関するタイムラインは連載510回で説明したが、2021年後半から2022年前半にインストールして、稼働は2022年後半である。
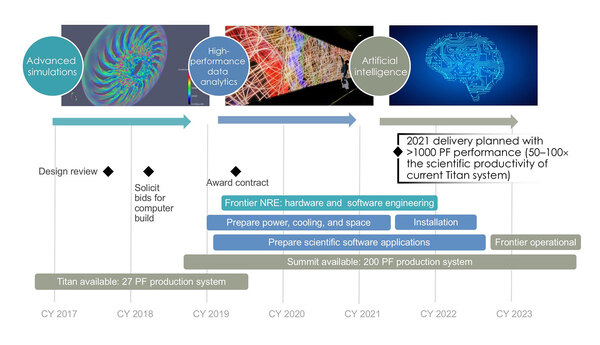
Frontierの導入スケジュール。CYはCalender Yearの略
ということは、とりあえずはMilanベースでシステムを稼働させ、途中でプロセッサボードを順次Genoaベースに更新していくという方法はアリである。
その一方でRadeon Instinctは少なくとも現在のMI100とはまったく違うカスタム版になると考えられる。こちらは少なくともI/Fとして以下の構成を取ると思われる。
- Infinity Fabricが6本
- CCIXとして利用できるPCIe Gen4 x16レーンが2本
- PCIe Gen4 x16レーンが1本
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ







































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")



























