




絶対性能はDGX A100の方がやや高速だが
DGX A100の価格はIPU-POD16の2倍
IPU-M2000の内部構成が下の画像だ。IPU同士は相互接続されるが、それとは別にIPU-Gatewayという名称の管理用のSoC(4コアの64bit Armコアだそうだ)とこれの起動用SSDと、それとは別に新たにDDR4 DIMMが搭載可能になっている。これは言わばIPU-M2000ごとに搭載されるローカルキャッシュであり、GraphCoreはストリーミングメモリーと称している。このストリーミングメモリーはIPU-Gatewayに接続される格好だ。
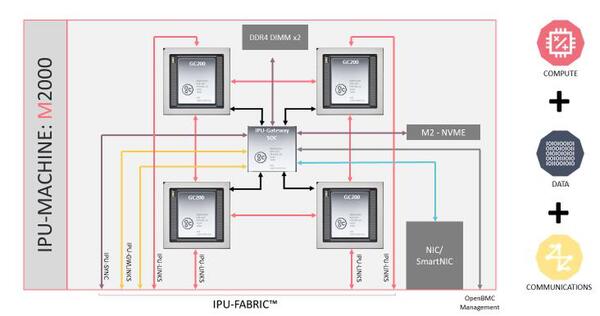
IPU-M2000の内部構成。大規模システムを構築するためには、やはり管理用プロセッサーもそれなりに必要という結論に達したらしい
IPU-M2000は単体でも動作するが、セット商品として4台(+x86サーバ)を組み合わせたIPU-POD16、16台組み合わせたIPU-POD64、さらにこれをクラウドサービスとして使えるGRAPHCLOUDの提供も始めている。

IPU-POD64の方は、手前にIPU-M2000の排気部が来ているのが見た目が違う理由である
ところでこのMK2の性能、当初説明があったのは「8台のIPU-M2000と16セットのNVIDIA DGX A100が同等(EfficientNet-B4のトレーニングでの数字)」という話であるが、これも漠然としている。ただこれについては、6月30日にMLPerf 1.0に準拠する数字を発表したということで、これに準じた数字がいくつか出てきたので説明しよう。
下の画像が、BERTとResNet-50のトレーニング時間である。全体のテスト結果はウェブサイトで公開されているが、ここからGraphcoreの製品の結果だけのダイジェストである。
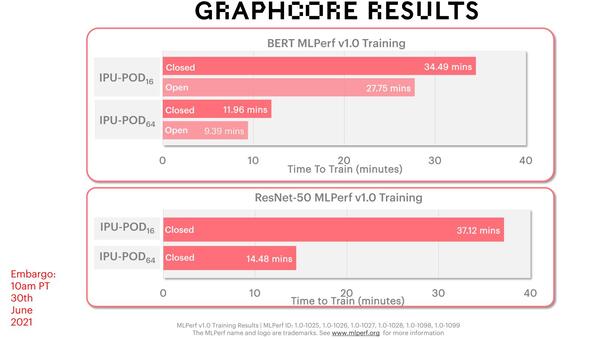
Open(Open Division Time)の方はほとんど結果がない(GraphCoreのものを含めて全部で5つしか結果が掲載されていない)ので、当面はClosed(Closed Division Time)の方だけを比較すればいいだろう
これだと比較にならない、ということでResNet-50とBERTの2つについて、NVIDIA DGX A100 640GBの結果と比較したのが下の画像だ。
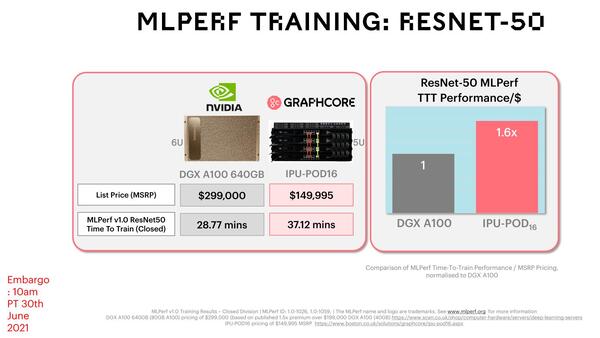
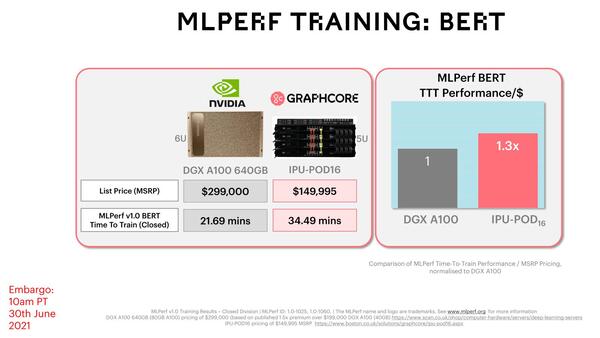
NVIDIA DGX A100 640GBと比較した結果
ちなみに「購入金額はともかく、実際には電気代の方が問題じゃないのか?」という指摘に対し、「MLPerfのテスト項目に消費電力が入ってないので正確な比較はできない」としたうえで、DGX A100の消費電力が6500W(なにせNVIDIA A100の消費電力が400Wで、これが8枚入る上にEPYC 7742×2とConnectX-6 VPIが複数枚装着されているから、GPUの分だけで考えてもフル稼働すると3000Wは固い)なのに対し、IPU-M2000は1100Wであり、4枚+Dellのサーバーの分を考えても5000W以下と考えられるので、運用コストでも有利、と説明があった。
絶対性能で言えばDGX A100の方がやや高速ではあるのだが、DGX A100の価格がIPU-POD16の2倍であることを考えると、IPU-POD16の方が1.3~1.6倍コストパフォーマンスが高いというのがGraphcoreの説明である。
MLPerfに入っていないテスト結果の一例がEfficentNet-B4のケースだが、こちらでは絶対性能で2倍、価格性能比で言えば3.8倍に達するという話であった。

DGX A100だけが競合ではない気もするのだが、一番ぶつかりやすいのがDGX A100なのかもしれない
Graphcoreが今後もAIプロセッサーの市場で戦っていくには、「次の製品」を確実に仕込んでいかねばならない。現状はA100と良い勝負ができているが、相手は湯水のように資金を投入して新製品を作ってくる。
とりあえず次は5nm世代に移行するのはかなり固いところで、これに今のMk2で競合するのは難しいだろう。NVIDIAに負けないペースで、Mk3を出せるかどうかが見ものである。
この連載の記事
-
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 - この連載の一覧へ

















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






































