




汎用のグラフプロセッサーとして設計された
第1世代のC2 IPU
そんなGraphcoreのIPUであるが、第1世代のC2 IPUをまずご紹介したい。そもそもIPUはグラフプロセッサーとして設計されたものである。もちろんニューラルネットワークそのものがグラフとして扱えるから、グラフプロセッサーはAIの処理に適しているかと言われればYesである。
グラフとして扱えるのはニューラルネットワークだけではないので、その意味では相対的に汎用向けとしても良いだろう。ただグラフプロセッサーでAI(というかニューラルネットワーク)を扱う場合の特徴として、人間と異なり構造そのものはスタティック(静的)に扱える一方で、その規模が猛烈に大きくなるという特徴がある。

O(xxxx)というのはオーダーの意味で、プロセッサーあたりの扱うItem(要素)が1000個オーダー、チップあたりで搭載されるプロセッサーコアが1000個オーダー、システムにはチップが1000個オーダーで搭載されるという意味になる。とにかく規模が大きいのが特徴という説明である
人間の脳で言えば、ニューロンが1000億個、シナプスが150兆個(概算値)とされており、1000×1000×1000でも10億にしかならないことを考えれば、そう誇張した数字とも言いがたい。ただ、人間の脳だとダイナミックにシナプスでの接続が変わることになるが、とりあえずそれは考慮しなくてもいいし、精度も比較的緩やかである。その代わりに通信量が猛烈なことになるという。

個数という意味では先に書いたようにシナプスがニューロンの1500倍ほどになるが、体積という意味ではこんな比率になるらしい
もう1つ考えるべきは、シリコンの効率である。Dark Siliconという言葉は2012年頃から言われ始めている言葉であるが、現時点でもまったく解決していない。
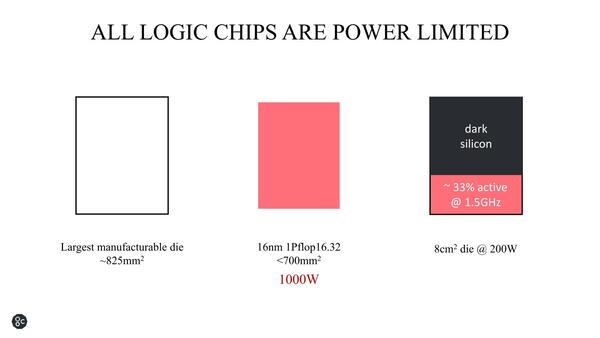
さすがに全部を演算器にするのは無理(データの入出力をどうするんだ?という話がある)ではあるが、1PFlopsの演算器(加算16bit/乗算32bit)をフルに動かすと1000Wになるというおそろしい試算である
現実にはデータパスやキャッシュなど、それほど発熱しない要素もあるわけで、これをうまく混在させることで発熱を抑える(というか、発熱箇所を均等にして、局所的に高発熱にならないように配慮する&全体としての発熱量を電力供給量や放熱能力と相談しながら制御する)必要がある。
この話と絡むのが、上でも少し書いたがキャッシュと演算器の電力密度の話である。1mm2に収められる演算器の数と消費電力は、やはりそれなりに大きくなる。fp16.32なら500pJ、fp32/fp64で480pJで、おおむね1mm2あたり500pJ/サイクルほど。これに対して同じエリアに256KBのSRAMを搭載できるが、その消費電力はアクセスあたり8pJほどとなる。
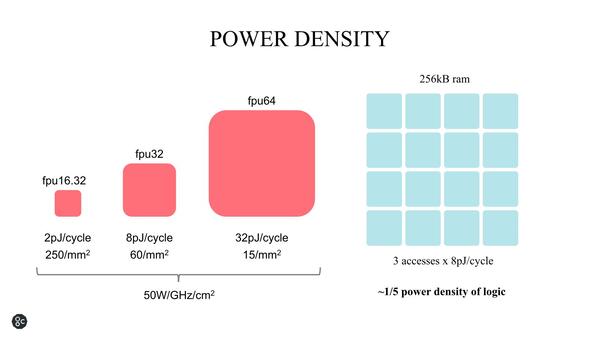
キャッシュと演算器の電力密度。この試算は16nmプロセスと思われる。DRAMと異なり、SRAMはロジックと同じ温度まで上がっても正常動作する点も大きい
もちろんキャッシュであればマルチポートになるし、バンク分けして同時アクセスすればそれだけ消費電力が増えるが、ラフにいってロジックの1/5となる。つまり、SRAMを適度にロジックと組み合わせることで、熱密度を下げやすいわけだ。これは、外部にDRAMを置くか、内部にSRAMを積むかという判断において非常に大きなポイントになる。
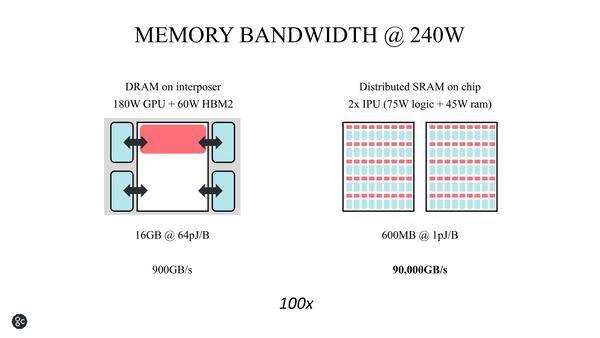
画像の右は、ダイサイズが必然的に肥大化する=原価が上がる、という問題である。歩留まりも悪化するので、このあたりのバランスが難しい
ダイサイズを節約できるという観点で言えばHBM2を外付けする方が効果的であるが、その一方で帯域が低く抑えられることになる。対してSRAM内蔵にすると、より帯域を広く取れる(=性能を高められ)、しかも熱密度を下げられることになる。GraphCoreは上の画像で右のアプローチをとったわけだ。
もう1つがコミュニケーション周り。ComputeとExchangeは常に発生するが、これを同時に実行する(Concurrent)と順に実行する(Serialized)のとどちらが効率が良いかという話である。
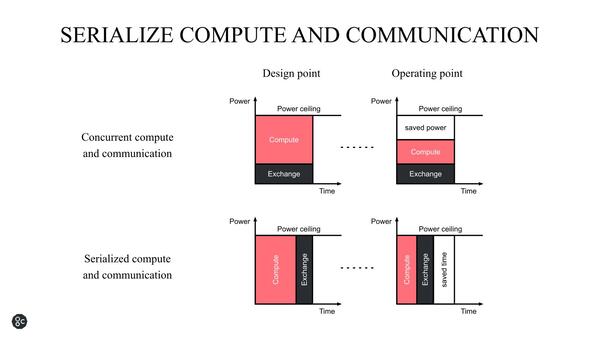
Concurrent方式は、Exchangeのレイテンシーを遮蔽できるという意味では、小さい規模の演算には向いている
これは一概にどちらが良いというものでもないのだが、GraphCoreは後者(Serialize)を採用した。というのは、Massive Processingの場合、単に自身の都合だけでExchangeが終わるとは限らないためだ。複数の前段の処理結果を受けて次段の処理が行なわれるケースでは、前段のある1つの処理のレイテンシーが遮蔽されたところで大して意味はない。むしろSerializeにした方が処理が楽になると考えたようだ。
具体的にはチップ内のSyncとチップ間のSyncという2種類の同期のタイミングに合わせてデータが交換され、各実行ユニットはデータが到着し次第処理を開始するというある意味非同期的な動作をする。
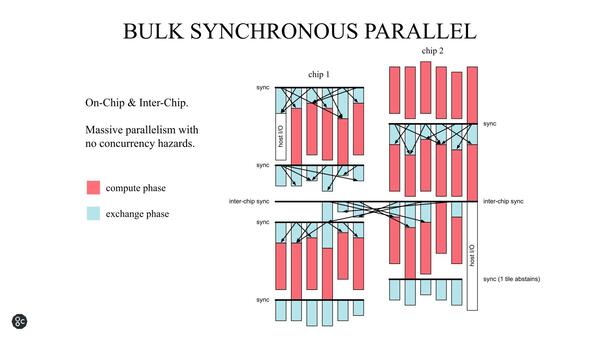
ある程度コアの数が増えると、コア間の同期がボトルネックになるのは見えているし、その際のレイテンシーは揺らぎがあるからDeterministic(決定論的)にスケジューリングはできない。であれば、もうこんな形に割り切った方が実装も楽だし効率が上がる、と判断したのだと思われる
処理が終わったら、次のSyncまで待つという意味で、広義には同期式であるが、そのタイミングがクロック信号ではなくData ExchangeのSync処理、というところがユニークな部分だ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第886回
PC
CFETの足を引っ張るPMOSを救え! imecが提案する新絶縁層と、あえて精度を緩める「Notch Alignment」の妙手 -
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 - この連載の一覧へ











、バッテリー駆動時間は13時間超え。もう欲しくなる要素しか見つからないッ!")








ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")
















