




IPUは7296スレッドの同時実行が可能なMIMDプロセッサー
下の画像がそのIPUの中身である。1つのIPUには1216のタイルがあり、それぞれのタイルはIPU-Coreと呼ばれるプロセッサーと256KBのSRAMから構成される。
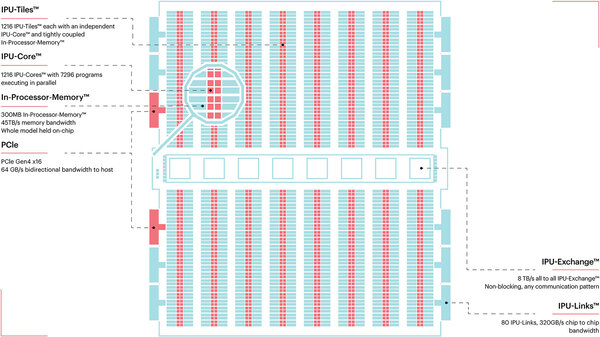
中央のブロックがIPU-Exchangeで、要はIPU-Core同士をつなぐ巨大なファブリックである
IPU-Coreは、同時に6つの実行コンテキストを保持できる。要するに6スレッドのSMT的な動きが可能になっている(厳密な意味でスレッドと言えるかどうかは議論があるところだが)。ということは1216×6=7296スレッドの同時実行が可能、という壮大なMIMDプロセッサーである。
ちなみにIPU-Coreのパイプライン構造などは公開されていない。ただ演算ユニットはかなり強力である。1216プロセッサーの合計処理性能はFP32で31.1TFlops、Mixed Precision(乗算は16bit、加算32bit)だと124.5TFlopsとされる。
IPUそのものは1.6GHz駆動とされるので、1サイクルあたり16Flops/プロセッサーの処理性能となる。つまり同時に16個のFP32演算が可能なわけだ。Mixed Precisionでは64演算ということになる。これは32bit×32bitの乗算器を4×16bit×16bitに構成できる、という話であろう。演算そのものはベクトル化されており、SIMD演算的に実行できるようだ。
これにつながるローカルメモリーはスクラッチパッドとして扱われる。そもそもIPUの場合、共有メモリーとなるものは一切存在せず、各IPU-Coreは自身につながった256KBのローカルメモリーがすべてである。したがって命令もデータも全部ここに収める必要がある。
これで不足する場合は、Exchange Phaseのタイミングで他からデータを持ってくるという動き方になるので、逆にどうやって256KBに収めるかが腕の見せどころではある。ただこうしたMassive Parallelの構成では1つのプロセッサーに長大なプログラムを実行させることは普通あり得ないから、むしろデータをどうやって収めるか、というあたりが最適化のポイントとなる。
ちなみにC2 IPUは単体というよりも2チップ構成で動くことを当初から想定しているようで、この2チップで2400コアあまりのIPU-Coreと608MBのSRAMを搭載するという、超Massive Processor構成となっている。
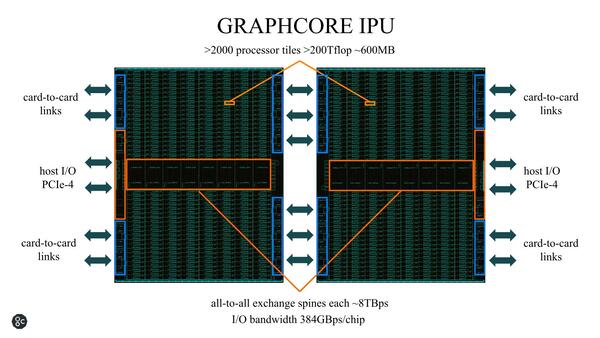
1枚のカードにC2が2つ搭載されるが、このカードを複数接続することを前提に、320GB/秒の帯域を持つIPU-Linkも搭載されており、PCIeとは別にこちらを利用して接続できるようになっている
さてこのC2 IPUの性能は? であるが、GraphCoreが当初発表していたのは、ResNet-50のトレーニングを16000枚/秒で処理するために必要なリソースは以下の通り。
| GraphCore | C2 IPUカード(C2が2つ搭載)×8枚 |
|---|---|
| NVIDIA | Volta V100カード×54枚 |
また2018年からは製品出荷されていたこともあり、いくつかの論文も出ている。例えば“Studying the potential of Graphcore IPUs for applications in Particle Physics”によればGAN(Generative Adversarial Networks)を実行する速度を以下の4つで比較した結果が下の画像だ。
| CPU1 | Intel Xeon Platinum 8168 |
|---|---|
| CPU2 | Intel Xeon E5-2680 v4 |
| GPU | Nvidia TESLA P100 |
| IPU | Graphcore Colossus GC2 |
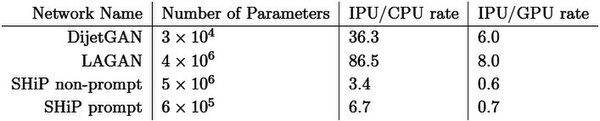
SHiP(The Search for Hidden Particles)experiencceは欧州のCERN(欧州原子核研究機構)における、タウニュートリノの検証を行なう実験計画。ここで利用されているのが下の2つのGAN Networkである
SHiP Prompt/Non-Prompt GANに関してはややGPUに後れを取っているが、CPUに比べれば圧倒的に高速だし、DijetGAN/LAGANなどではGPUと比べて十分に優位性がある、という結果である。
あるいは2020年末に“Hardware-accelerated Simulation-based Inference of Stochastic Epidemiology Models for COVID-19”という、新型コロナウイルスの疫学モデルをシミュレーションで実施したという論文では、C2 Card×2とTesla V100、Xeon Gold 6248×2と比較して圧倒的に高速であるという結果が示されるなど、単にAI以外の用途にも利用できることなどが示されている。
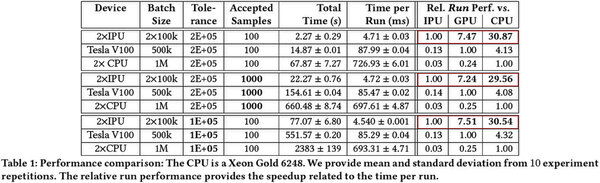
赤枠は筆者が追加。この赤枠部分がGPUないしCPUとの相対性能ということになる
さて、この第1世代IPUはTSMCの16nmで製造されていたわけだが、数回にわたる資金調達のおかげもあり、無事に第2世代IPUを2020年7月に発表した。

Colossus Mk2 GC200 IPU。一見するとMk1とよく似ているが、ダイの脇にあるコンデンサーの配置などが大きく異なる
第1世代のC2ことColossus Mk1 GC2 IPU(第2世代の投入に合わせて名前が変わったようだ)は16nmプロセスで236億個のトランジスタを集積、ダイサイズは700mm2を超えていたが、第2世代のColossus Mk2 GC200 IPUではTSMCの7nmプロセスに移行。ダイサイズは823mm2、トランジスタ数は594億個と、ほぼTSMCで製造できる限界に近いサイズに挑戦している感がある。
ただ内部構造を見ると、Mk1とよく似ている。IPU-Tileの数は若干増えて1427個になり、またタイルあたりのSRAM容量は256KBから624KBに増量されている。この結果、IPUのSRAM容量は900MBに達している。
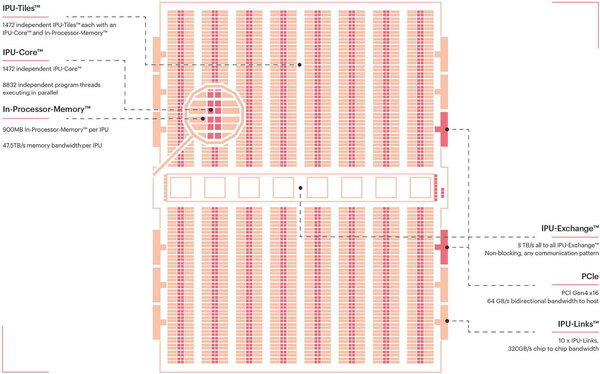
Mk2の内部構成。基本的な構造そのものは同じに見える
その一方で、性能に関しては「実際のアプリケーションの場合でMk1の8倍の性能に達する」としている。ここでのポイントは「同じ演算処理を8倍高速に実行する」とは言ってないことだ。

これはそもそもMk1を2つ搭載したPCIeカード×8 vs Mk2を4つ搭載したM2000×8なので、まずチップの数からして違っているのだが
例えばBERT-Large Trainingであっても、同じ精度で実施しているとは一言も言っていない。Mk2では従来のFP32およびMixed Precision(FP16.32)に加え、FP16.16(乗算・加算ともに16bit)およびFP16.SR(確率的丸め処理付きFP16)を追加しており、データ型としてこちらを使っている可能性もある。実際4×Mk2ではFP16.16で1PFlopsの演算性能と同社は説明しており、Mk2が1つあたり250TFlopsである。これはFP16.32で124.5TFlopsだったMk1の2倍になる。
またMk1では、バッチサイズが大きくなると256KBのSRAMでは足りなくなって性能が低迷する傾向が見えていたが、これがSRAMの大容量化で大きく緩和された可能性もある。
これに加えてMk2世代ではシステムレベルでの強化も行なわれた。Mk1世代はPCIeカードでの提供のみだったが、Mk2世代ではIPUを4つ搭載した1UのブレードサーバーであるIPU-M2000として提供されることになった。

Mk1世代。ものすごい見かけであるが、2スロット厚のPCIeカードである

Mk2世代。中央に4つ並ぶヒートシンクの下にそれぞれColossus Mk2 GC200 IPUが鎮座している
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 -
第873回
PC
「銅配線はまだ重要か? 答えはYesだ」 NVIDIA CEOジェンスンが語った2028年ロードマップとNVLink 8の衝撃 - この連載の一覧へ









































ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












