





LaMDAによる、紙飛行機に関する人とコンピュータの対話例。非常に自然な会話になっている点に注目
「LaMDA」と「MUM」はGoogle検索の姿を改革する
次の大きな発表が「LaMDA」と「MUM」だ。
現在、コンピュータに対する問い掛けは、自然な会話にはほど遠い。1つの質問を1つのキーワードで表す「検索キーワード」を入れるのがもっとも有効であり、文章の形で入力できるサービスは限られている。音声インターフェースでも、決まったキーワードを発し、それを認識している状況に近い。
それを「ちゃんとした会話」に近づけるのが「LaMDA(Language Model for Dialogue Applications、対話アプリケーションのための言語モデル)」だ。「まだ研究開発の初期段階(グーグルのスンダー・ピチャイCEO)」というが、デモを見る限り、かなりスムーズな会話が実現できている。
コンピュータとの会話は、特定のキーワードや内容に関するものを行う「エージェント型」が多い。特定の内容に特化しているので、どうしても話の範囲は限定的だし、関連する内容でも深掘りすると対処できる範囲を外れることが多い。だが、LaMDAはそうではなく、テキストから学習した内容に基づき学習をすることで、特定の内容に限定されることなく、毎回違う会話パスをたどり、多彩で自然な会話による返答を実現する……とされている。
グーグルがLaMDAに関する解説サイトに掲載しているイメージ。特定の領域に止まることなく、複雑で広範な領域について会話のパスがつながることを示している ※画像をクリックすると、グーグルのLaMDAサイトに移動します
だが、これだけでは「人に問いかけるような自然で多彩な解答」を実現するには不足している。1つの問いかけの中には、テキストからの情報だけでなく、映像・写真など「複数の情報からの知見」を必要とする場面は多々あり、その結果として自然な会話として返す必要があるからだ。SFの中に出てくるような「相手が人間と同じレベルで対話できるコンピュータ」を目指す場合には、自然な会話ができる技術と、回答に必要な複数の知見を同時に解決する技術の両方が必須になる。
複数の情報ソースをまとめて処理する技術が「MUM(Multitask Unified Model、マルチタスクによる統合されたモデル)」だ。

ピチャイCEOは、「コンテンツの種別を横断し、統合した形で会話・解答を行う必要がある」と解説する
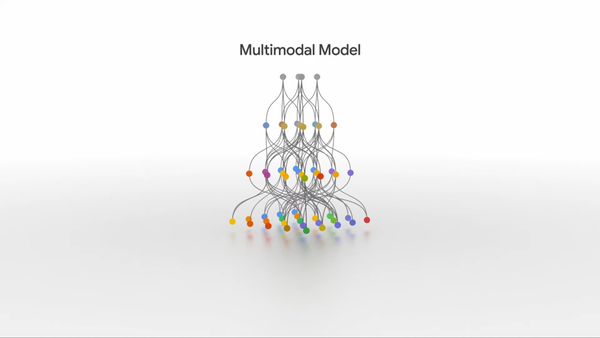
MUMでは問いかけの中から必要なキーワードをピックアップし、そこで必要になる情報を文字・写真・動画などの多彩な情報ソースを並列に活用して答えを返す。例えば「富士登山についての問いかけ」なら、そこでは、文字と写真のように種別が違う情報だけでなく、言語が違う情報も並列に扱われる。現在は、75の言語に対応しているという。

MUMは世界を深く理解し、75以上の言語をまたいで様々なコンテンツに関する回答を出すことができる
MUMは、現在グーグルが検索エンジンのための自然言語理解に使っている「BART」に比べ1000倍以上優れている、と同社は主張する。数カ月以内にグーグルにおける特定の検索内容向けに、試験的に導入が開始される予定だ。

MUMの検索効率は、現状のBARTに比べ1000倍以上優れている、とされている
こうした技術が示す、グーグルの方向性は明確である。
いままで、グーグルはウェブページを探す「検索エンジン」と呼ばれてきた。だが、グーグルが目指すのは、単にウェブページを並べて出すことでなく、各ウェブページをもとに「答えはここにあるでしょう」と示すことだ。解答のための会話こそがグーグルにとっての「結果」であり、ウェブページはその先にある情報、といってもいい。今もいくつかの情報については、ページのリストの上や横に「解答」のような形で情報が出ているが、それがさらに拡大されていく、と考えればいいだろうか。
MUMで多彩な情報をまとめて処理しつつ提示し、LaMDAで会話形式にする。そうなると、ウェブの情報を使うための方法は「見る」ことに限定されなくなっていく。今の音声アシスタントは不完全なものだが、MUM+LaMDAで得られた結果でコミュニケーションが行えるようになれば、音声による機械とのコミュニケーションの可能性はずっと大きなものになる。
ウェブ広告に絡むエコシステムなどが変わってしまう可能性も秘めているので、その影響も含め、視野を広くしておきたい部分ではある。
本記事はアフィリエイトプログラムによる収益を得ている場合があります




























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






























