




畳み込みニューラルネットワーク向けの
アクセラレーター「NeuPro」を開発
このあたりからCEVAでは明確にAI/MLがCEVAの将来の市場として有望という感触をつかんだようで、ここから畳み込みニューラルネットワーク向けのアクセラレーターの開発を始めている。もともとCEVA-XM6の説明のプレゼンテーションの中に、CDNNに特化したアクセラレーターを開発するという話が出てきていた。

このアクセラレーター、当時は「将来CEVA-XM6用のコプロセッサー的な形で発表され、オプションとして利用可能になる」といったニュアンスで説明されたと記憶している
実際この連載でも説明してきたが、畳み込みニューラルネットワークにしてもすべてのデータがフルに入っている状態というのは少なく、しばしば疎のデータが来る場合がある。これはデータに依存する話なので、事前にネットワークを最適化したところで避けられるわけではない。
これをバカ正直に処理すると無駄に時間と電力を喰うので、それこそデータフローのような仕組みを入れて疎のデータを動的に弾いてしまうことで効率を上げようと考えるわけだが、この仕組みをDSP全体に入れてしまうのは大変である。
そこでこうした部分は専用のアクセラレーターを利用することで、MACユニットの効率を引き上げ、性能を改善しようというわけだ。これは最終的に2018年1月にNeuProとしてリリースされる。
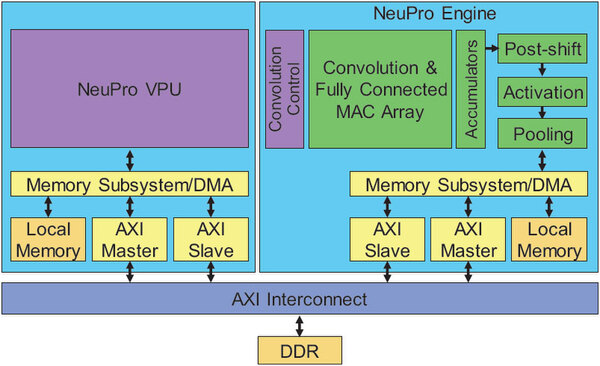
NeuPro VPUの方はCEVA-XMベースのDSPをそのまま流用する格好で、NeuPro Engineの方がメイン
画像の出典はMicroProcessor Reportの2018年1月号
要するに疎のデータを弾くといった機能を追加し、さらに活性化やプーリングまで含まれた、畳み込み演算に特化したアクセラレーターを核にしたものだ。このNeuProエンジンはNP500/NP1000/NP2000/NP4000の4つの構成があり、それぞれ1サイクルあたりに512/1024/2048/4096MAC演算を可能としている。
ちなみにこの数字は8bit×8bit演算の場合だが、混合精度もサポートしており、例えば8bit×16bit演算なども可能である(その場合性能はやや落ちるが)。このNeuProは16FF+プロセスを利用した場合1.53GHzで動作し、ピーク性能は6267GMAC/秒に達するとしていた。これは当時の競合製品に比べて1.5~5倍程度高い数字である。
このNeuProをさらに進化させたのが、2019年に発表されたNeuPro-Sである。NeuProエンジンそのものにも拡張がいくつか施された他、マルチコアに対応。さらにカスタムAIエンジン(これは顧客が構築するもの)を追加することも可能になった。
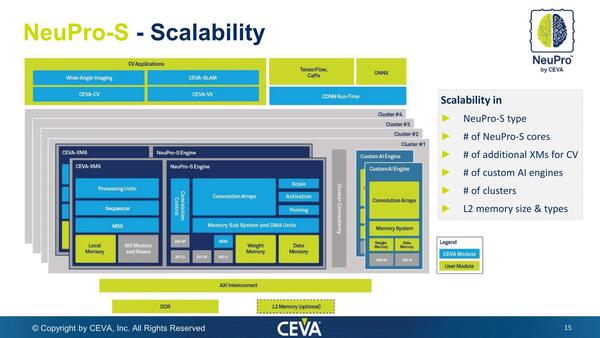
大幅にスケーラビリティー、つまり要望に応じてコアを増やしたり拡張したりする余地を増やしたのが最大の特徴である。どこまで増やすかはコスト(=ダイサイズ)や消費電力との相談になるわけだが
個々のNeuPro-Sエンジンのピーク性能そのものはNeuProエンジンと変わりないが、1コアで最大12.5TOPS、マルチコア構成では最大100TOPS以上の性能も実現可能となった。こうなってくるとターゲットはさらにシビアな用途も視野に入るわけで、実際NeuPro-Sを利用してLevel 4~5の自動運転も可能とCEVAは説明している。
CEVAはその後、AIを利用しつつもIoT向けなどに多数のセンサーをつなげて、これを処理するセンサーハブ向けのCEVA SensPro2や、5G基地局に向けたCEVA-PentaG、5Gモデム向けのCEVA-XCシリーズといった特定用途向けDSPに加え、汎用のCEVA-BX2や省電力向けのCEVA-X1など、多数のバリエーションを展開しており、オーディオ/ビデオ向けといったもともとの用途に加えて非常に広範な市場をサポートしている。
AI/ML向けアクセラレーターと異なり、NeuPro-Sですら(使おうと思えば)「汎用DSPとしても使える」あたりが同社の強みになっているのは間違いない。AI推論向けの市場で、特にエンドデバイスではこのCEVAのシェアが割と少なくない。
もともと別の用途向けにCEVAのDSPを入れてあるデバイスのファームウェアを書き換えるだけでAI対応ができるようになる、というのは最終製品の付加価値を後追いでも追加したいベンダーにとっては非常に都合の良いシナリオであり、こうした市場をうまくつかんでビジネスにつなげているのがCEVAというわけだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ




















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























