




CEVA Inc.はDSP Groupの
プロセッサー販売専門会社
話を戻すと、DSP Groupはやはり音声向けDSPを、主に電話、それも音声自動応答システムやビジネスホンなど、高付加価値系の電話や、初期のデジタルコードレスホンなど投入するとともに、携帯電話ビジネスにも参入していく。
このうちコードレスホンのビジネスはAMDに、携帯電話ビジネスはインテルにそれぞれ買収された。DSP Groupそのものはマルチメディア系やWi-Fi、ケーブルモデムなどにフォーカスしていくが、この途中でDSPのコアそのものをIPとして外販するビジネス部隊を独立させた。これがCEVA Inc.である。
ちなみにDSP Groupそのものは2007年にNXPに買収されてしまっており、現時点ではCEVAが唯一残ったビジネスユニットということになる。CEVAそのものはまだ創業20年に達していないが、DSPそのものは30年以上に渡って手掛けてきたという、やや辻褄が合わないことになっている。
というわけでそのCEVAの話だ。同社はArmと同じくDSPのIPを提供するベンダーであり、目立たないところ、例えば携帯電話の無線側の処理を行なうベースバンドチップなどには、一時期90%を超えるシェアを獲得するなど、かなり広い範囲で利用されていた。
また、ここ数年は音声向けとしてヘッドフォンなどにも広く使われるようになってきている。そうした中で同社が見つけた新たな市場がAI/ML向けだったというわけだ。
先にも出てきたがDSPはとにかく積和演算を高速に処理するのが主目的のプロセッサーであり、そしてAI/MLの中でも特に畳み込みニューラルネットワークなどは積和演算が非常に多いわけで、どう考えてもDSPで処理するのにぴったりとなる。
そこで、CEVAはまず同社の既存DSP IPの上で動作するCDNN(CEVA Deep Neural Network)というソフトウェアフレームワークを2015年に発表した。
CDNNは下の画像にあるように、まず既存のCaffe/TensorFlow/ONNX(ONNXは2018年に追加された)といったフレームワークで学習を行ってネットワークを構築する。この構築されたネットワークを、CDNNコンパイラを使って変換することで、CEVAのDSP上で動作する仕組みだ。
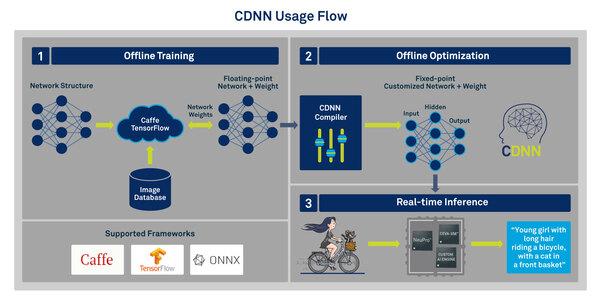
CDNNの概要。さすがに動的にネットワークを解釈して実行させるというのはDSPには荷が重いわけで、あらかじめDSPに最適化させる形でネットワークを作り直し、これを動かすことになる
このCDNN、当初想定していたのはCEVAが2015年3月に発表したCEVA-XM4というDSP IPである。
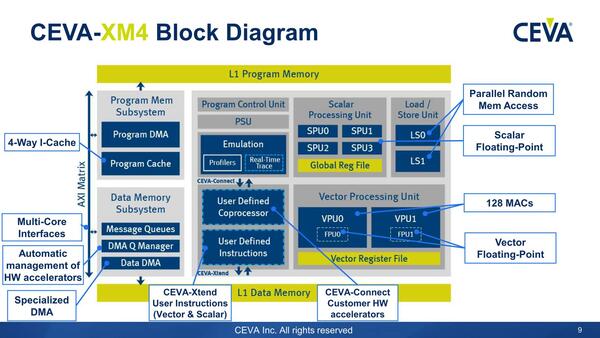
CEVA-XM4の内部構造。IPを購入したベンダーが、独自に命令を拡張したりコプロセッサーを追加したりも可能になっている
4つのスカラーエンジンと2つのベクトルエンジンを持つこのDSP、スペックとしては以下の特徴を持つ。
- 最大128MAC構成で、それぞれが8-wayのVLIWになっており、最大構成だと4096bitのベクトルを処理できる。
- 内部パイプラインは14段。TSMCの28nm HPMで1.5GHz動作を保証
- メモリーアクセスは32wayのインターリーブで、それぞれ独立にアクセス可能
- 2次元メモリーアクセス(行列の転置やFFTなどで、行と列をひっくり返してアクセスする)をサポートするSliding Window/Sliding Patternをメモリーアクセスでサポート
- 8/16/32/64bitの浮動小数点と固定小数点演算をサポート。スカラーでは浮動小数点/固定小数点ともに4 MACs/サイクルだが、浮動小数点で16 MACs/サイクル、ベクトルでは128 MACs/サイクルの処理が可能
- 特殊計算(1/x、√x、1/√x)を1サイクルで処理できる
もともとCEVA-XM4は画像処理向けとして開発されたもので、当初の目的は例えば3D Vision(ステレオカメラを利用して対象物の3次元イメージを構築)や、カメラ画像の補正(超解像、デジタルズーム、輝度拡張、スタビライジング)などを目的にしていた製品だが、CDNN発表後にはこれに加えて物体認識や対象物追跡、物体分類や汎用の畳み込みニューラルネットワークなども目的に追加されることになった。
CEVA-XM4の後継として2016年に投入されたのがCEVA-XM6である。基本的にはまだVision DSPというカテゴリー向けの製品ではあるが、特に畳み込みニューラルネットワークの処理に向けて最適化を図っており、ベクトル処理でCEVA-XM4比で3倍、平均で2倍の性能改善を施し、かつ制御コードの柔軟性も50%増加したとされる。
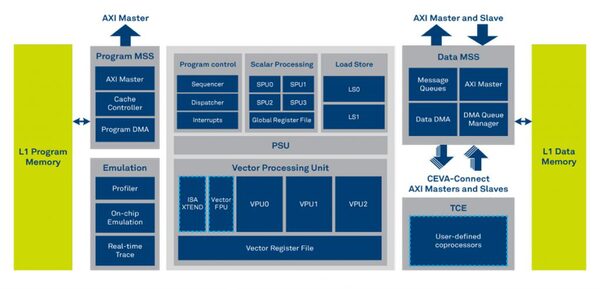
CEVA-XM6。SPU(System Processing Unit)の数は変わらないが、VPU(Vision Processing Unit)が1つ増えたほか、細かな改良が施されている
またCEVA-XM4で動くコードはそのままCEVA-XM6でも動作するとしている。TSMCの20nmで試作された690MHzで動作するCEVA-XM6とNVIDIAのTX1でのAlexNet/GoogleNetの処理性能の比較では、CEVA-XM6の性能が4倍、性能/消費電力比が25倍になったという数字も示されている。
CDNNもCNDD2にバージョンアップされ、ワンボタンで変換が可能になったほか、対応するネットワークの数も大幅に増えた。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 -
第873回
PC
「銅配線はまだ重要か? 答えはYesだ」 NVIDIA CEOジェンスンが語った2028年ロードマップとNVLink 8の衝撃 -
第872回
PC
NVIDIAのRubin UltraとKyber Rackの深層 プロトタイプから露見した設計刷新とNVLinkの物理的限界 - この連載の一覧へ









































ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")









