



NVIDIA A100 GPUを最大8個搭載可能、第2世代AMD EPYCとの組み合わせで「究極の性能を引き出す」
HPE、AI/HPCプラットフォーム「Apollo 6500 Gen10 Plus System」を発表
2021年01月29日 07時00分更新

日本ヒューレット・パッカード(HPE)は2021年1月27日、第2世代AMD EPYCプロセッサとNVIDIA A100 Tensor Core GPUを搭載したエンタープライズ向けAIプラットフォーム「HPE Apollo 6500 Gen10 Plus System」を発売した。「最高性能のCPUとGPUによって究極の性能を引き出すことができるとともに、幅広いワークロードに対応する柔軟性を持ち、TCO削減にも貢献できる」(HPE HPC&AI/MCS事業統括カテゴリーマネージャーの高橋健氏)としている。
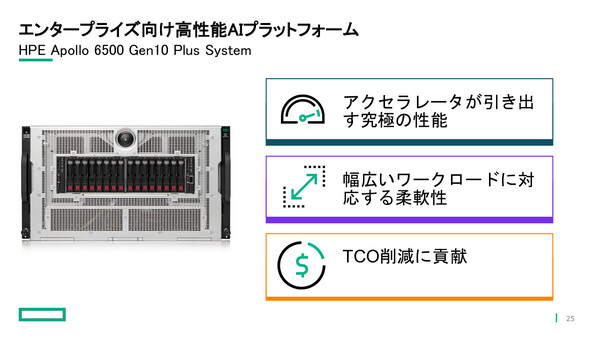
HPEが発表したAIプラットフォーム「HPE Apollo 6500 Gen10 Plus System」の特徴


日本ヒューレット・パッカード 取締役 執行役員 HPC&AI/MCS事業統括の根岸史季氏、同事業統括 カテゴリーマネージャーの高橋健氏
NVIDIA A100 GPUを最大8個搭載、柔軟に構成できるAI/HPC向けサーバー
Apollo 6500 Gen10 Plus Systemは、6Uサイズのシャーシにコンピュートモジュール、GPUモジュール、ストレージ、冗長電源、空冷ファンなどを組み込んだHPC/AI用途向けの高性能サーバー。コンピュート/GPUモジュールは、フルワイドの「ProLiant XL675d Gen10 Plus」とハーフワイドの「ProLiant XL645d Gen10 Plus」の2種類をラインアップしており、用途に応じて選択できる。

Apollo 6500 Gen10 Plus Systemのシステム概要。フルワイド/ハーフワイドのGPU/コンピュートモジュールを用意している


Apollo 6500 Gen10 Plus Systemの特徴と、NVIDIA A100 GPUを8個搭載できるフルワイドの「ProLiant XL675d Gen10 Plus」の概要
GPUモジュール部には、前世代(V100)比で20倍のAIスループットを実現する「NVIDIA HGX A100」GPUを最大8個搭載できるほか、HPC向けGPU「AMD Instinct MI100アクセラレータ」、その他のPCIeカード型GPUを柔軟に組み込むことができる。シングルワイドPCIeカード型GPUの場合は、最大16個を搭載可能。
コンピュートモジュール部には、第2世代AMD EPYCプロセッサを最大2個搭載可能。EPYCプロセッサには幅広い周波数/コア数/消費電力の選択肢があり、最高性能を持つ「AMD EPYC 7H12 2.6GHz 64コア(280W)」もサポートしている。さらに「NVIDIA Mellanox HDR InfiniBand」との統合により、最大1000Gbpsの通信帯域も確保する。
排熱対策のためシャーシ内ではCPUとGPUエリアが分離されており、15個のファンによる空冷を行う。さらにラック型水冷システム「HPE Direct Liquid Cooling(DLC)」もサポートしており、さらなるCPU/GPU性能の安定と故障率の低減が実現できる。
またApollo 6500 Gen10 Plus Systemは、HPE Crayスーパーコンピューター向けの「HPE Slingshot」インターコネクトと結合することも可能。サーバーOSとして「HPE Cray OS」もサポートしている。
希望小売価格は最小構成で502万5000円から(税抜)。従量課金制の導入モデル「HPE GreenLake」の利用も可能だ。
なお東京本社(江東区大島)内の「HPE AI研修センター」に、NVIDIA A100 GPU×8個を搭載したApollo 6500 Gen10 Plus Systemを配備したことも発表している。オンサイトでそのハイパフォーマンスを体感できるほか、VPN経由のセキュアなリモート検証にも対応している。HPEのAIスペシャリストによる支援も提供する。
コンテナプラットフォーム「Ezmeral」とのパッケージ製品も提供
発表会では、HPEのAI領域における取り組みについても説明した。
HPEでは、顧客企業におけるAI戦略策定から導入、活用までのロードマップを一貫して支援するデータコンサルティング「HPE Pointnext Technology Services」、分散データの統合と開発サイクルの自動化/効率化を可能にするコンテナ基盤「HPE Ezmeral Container Platform」、従量課金制で低リスクかつ迅速にAI戦略を実現可能にする「HPE GreenLake」などを通じて、“エッジからクラウドまで”をまたぐデータパイプラインを最適化する製品/サービスを提供している。
「データの収集/集約/学習/推論までを自社製品だけで、Edge to Cloudにまたがるデータパイプラインポートフォリオを揃えているのがHPEの特徴であり、必要な処理性能を必要な場所で利用できる」(HPE HPC&AI/MCS事業統括 AIビジネスデベロップメントマネージャーの山口涼美氏)
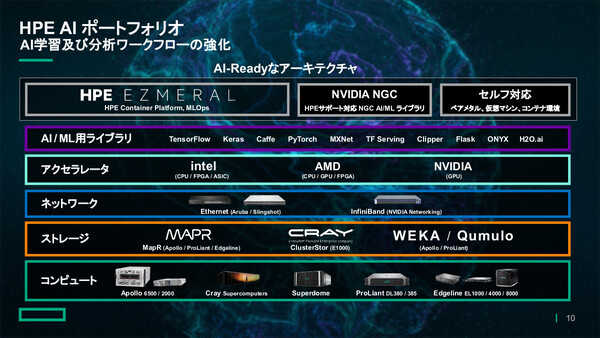
HPEのAI関連製品ポートフォリオ
さらに、小規模学習向けからコンテナ型の本格的AIソリューションまで、規模や用途に合わせた4つのAIソリューションパッケージを提供することも発表した。このうち「AI Training Kit」および「GPUaaS System」には、HPE Apollo 6500 Gen10 Plus Systemを採用している。
「4つのAIソリューションパッケージは、要求の厳しいHPC/AI/ML(機械学習)/DL(ディープラーニング)のワークロード向けにテストを行い、事前構成済みソリューションとして提供する。本番環境にもスムーズに移行できる」(山口氏)

このうちGPUaaS Systemでは、Apollo 6500 Gen10 Plusサーバーをコンテナオーケストレーション環境として構成し、「TensorFlow」や「PyTorch」といった学習フレームワークをコンテナとして導入、各コンテナにGPUなどの計算リソースを柔軟に割り当てることができる。これによってリソースの有効配分、開発環境構築時間の短縮、バージョン管理が容易となり、開発効率が飛躍的に向上すると説明した。
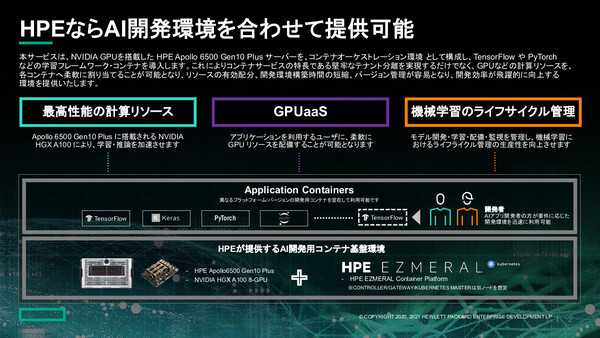
最上位パッケージの「GPUaaS System」は、Apollo 6500 Gen10 PlusとNVIDIA A100 GPUにHPE Ezmeralコンテナ基盤を組み合わせて提供する
組織横断のAIビジネス推進チーム、付加価値コンピューティング分野の統合事業部
HPEでは昨年(2020年)、全社横断のAIビジネス推進チーム「HPE JAPAN AI CROSS-BU」を設置した。同チームはAIビジネスに関係する製品/サービス/セールス/マーケティングの各事業部人員で構成されており、HPEグローバルのAI戦略チーム「HPE WW AI Ambassador」とも知見を共有しながら、HPEの持つ豊富なポートフォリオと専門人材/組織の活用、パートナーエコシステム強化、パートナー向け人材教育プログラムの提供などに当たっている。こうした活動を通じて、日本の顧客におけるAI活用を加速していく狙いだ。
また、付加価値の高いコンピューティング分野(Value Compute分野)を幅広く対象とするHPC&AI/MCS事業統括(通称:HAM括=ハムカツ)の取り組みについても説明された(MCSはミッションクリティカルソリューションズの略語)。
HPE 取締役 執行役員 HPC&AI/MCS事業統括の根岸史季氏は、同事業部は要件の異なる幅広い領域を対象とするものの「システムとしての信頼性、性能などを追求した際に、サーバーの構成要素は同じ」であり、そこに搭載するミドルウェアやソフトウェアによって「方向付けが明確にできる」と説明した。
「信頼性を追求するのであればNonStop OSであり、性能を追求するのであればSchedulerやMPI Libraryを活用する。HPC、MCS、エッジコンピューティングは、ベクトルが異なる要素に見え、お客様も別々であるため、異なる事業部門が対応するのが一般的だったが、ストラクチャーが似ている点に注目した。そして『AIをサポートするインフラ』という点においては、HPC、MCS、エッジを兼ね備えたシステムが要求されている」(根岸氏)
「AI活用」というニーズを軸に据えて考えた場合、HPC、MCS、エッジコンピューティングが縦割り組織で分断されているままでは到達しえない領域があり、ひとつの事業部門でシステムをデザインすることが必要だと考えたという。そこでHPC&AI/MCS事業統括という形で統合し、製品開発と営業活動、顧客の声が反映できる一体組織にしたと、狙いを説明した。
本記事はアフィリエイトプログラムによる収益を得ている場合があります



