




精度重視のためサポートするのは
INT 8ないしBFloat16のみ
さて価格や性能はおいておくとして、Flex Logicはどうやってこれを実現したか? であるが、基本的な流れは下の画像の通り。64サイクルが一つの区切りになっており、Load/MAC/Saveをパイプライン式に行なえるようになっている。

TPUを2次元構造に並べるベンダーもいくつかあるが、常に2次元を使い切れるとは限らないのが欠点。一方で1次元構造なら、効率は良いものの複雑なネットワークでは通信のレイテンシーが大きくなるという問題もある
ちなみに同社の基本的な発想は精度重視だそうで、それもあって例えばFPGAなどで多用されるBinary(Int 1)やInt 4などのデータ型は使われず、サポートされるのはINT 8ないしBFloat16になっている。
BFloat16では指数部8bit/仮数部7bit(+符号)なので、INT 8の演算エンジンがそのまま流用できるので、都合が良いということだろう。上の画像でINTだと64 MACsなのにBF16だと32 MACsというのは、2つのMACユニットで1つのBFloat16を処理しているのだと思われる。
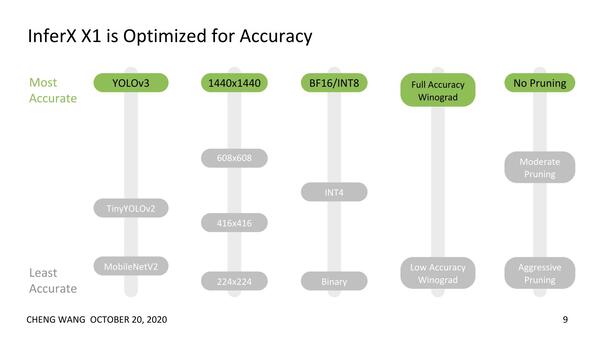
InferX1は精度重視。Winogradは畳み込み演算を高速化するアルゴリズムのこと
このTPUが16個と、他にFPGAロジック(図中のEFLX Logic)や2MBのL2 SRAM、それとXFLX Interconnetが組み合わさって1つのブロックを形成。InferX X1にはこれが4ブロック実装されるので、TPUは合計で64個、L2 SRAMは8MBとなる。
おのおののTPUにはMACユニットが64個あるので、トータルで4K MACsということになり、それなりの演算密度ではあるのだが、InferX X1の最大の特徴はこのXFLX Interconnectにある。

L1 SRAMは、64×256個のWeightを格納するためのものなので、16KBに収まっている。これが4つで(ブロックあたり)64KBに過ぎない
上の画像にも“Tensor Processors are Reconfigurable”とあるが、なにがReconfigurableか? というとTPUそのものではなく、TPU同士をどうつなぐかを動的に変更できるというものである。
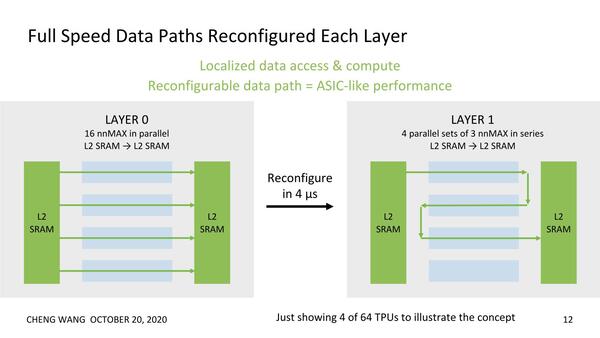
例えばある層では、16個のTPUが並行して動作するが、別の層では3つのTPUを連結して動かすという場合に、XFLX Interconnect内のつなぎ方を動的に変更可能になる
Reconfigurationは4μsで(つまり1秒間に最大25万回)変更が可能とされている。これで十分かというと、扱うデータ量やネットワークの層数に依存するが、例えば100fpsを実現したいと思うと、1枚あたり2500回のネットワーク変更が可能なので、普通に考えれば十分であろう。
ちなみにこうした複数のTPUを連続して動かすケースでは、ある段のTPUの出力が(そのままメモリーなどを介さずに)次のTPUに渡せるので、メモリー帯域の節約にもなるしボトルネックの削減にもなるとしている。
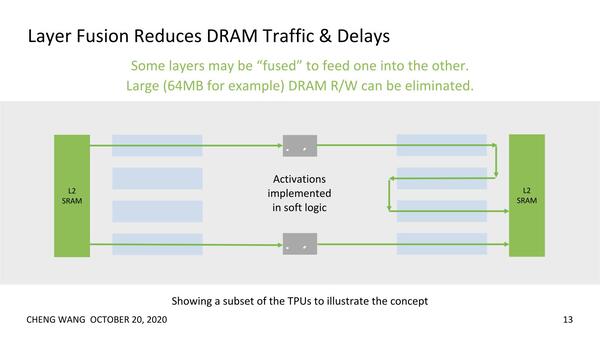
TPUで扱えないような特殊な処理は、EFLX Logicを利用して実装可能である。これが“Activation impremented in soft logic”の意味である
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 -
第873回
PC
「銅配線はまだ重要か? 答えはYesだ」 NVIDIA CEOジェンスンが語った2028年ロードマップとNVLink 8の衝撃 - この連載の一覧へ











&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")




















ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












