ロードマップでわかる!当世プロセッサー事情 第588回
Ryzen 5000シリーズはなぜ高速なのか? 秘密はZen 3の内部構造にあり AMD CPUロードマップ
2020年11月09日 12時00分更新

スケジューラーの構造を大きく変更した
バックエンド
次がバックエンドである。先にも書いたが、Integer(整数演算)が最大8イシュー、Float(浮動小数点演算)が最大6イシューとなり、その意味ではどちらも同時実行命令数は増えてはいるのだが、やや筆者の予想と異なる最適化の方向性になっていた。
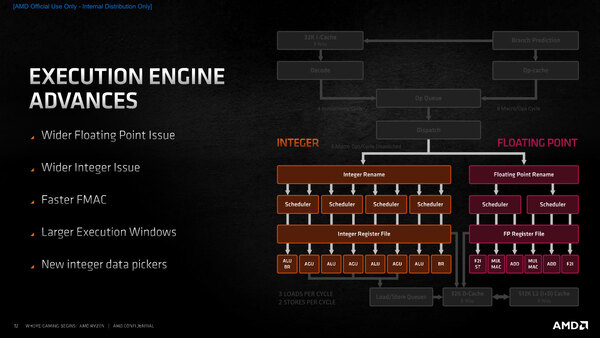
バックエンドの構成。スケジューラーの構造変更が最大のポイントかもしれない
このレベルでの最大の相違点はスケジューラーの変更だ。Zen/Zen 2は、AGUとALUを別々に扱うという仕組みで、であれば7つの発行ポート全体をカバーするスケジューラーにした方が効率が良いという判断であった。この発想はインテルとかなり近い。これに対してZen 3では以下の4つに分解されることになった。
| Zen 3のスケジューラー | ||||||
|---|---|---|---|---|---|---|
| Scheduler 0 | ALU0+AGU0 | |||||
| Scheduler 1 | ALU1+AGU1 | |||||
| Scheduler 2 | ALU2+AGU2 | |||||
| Scheduler 3 | ALU3+BRU1 | |||||
これはなぜかと言えば、おそらくだが実際に実行中のプロファイルを取ってみると、予想以上にメモリー演算が多かったのだろう。そもそもRISCの場合、演算命令はレジスターに対して行なう形で、メモリーアクセスが可能なのはロード/ストアー命令に限られている。だからこそAGUとALUは別々に動かしても問題ないという発想である。
これはx86も同じで、x86なりx64そのものはCISCであるが、Micro-Opに変換した段階でRISC風になっているため、ALU命令そのものはすべて内部のレジスターに対して行なう形となり、これとは別にメモリーからレジスターへのロード命令が自動的に生成される形になる(ストアーに関しては原則として、x86/x64でも明示的に命令を発行する必要がある)。
ただ、そうした「メモリーからのロード+演算」の組み合わせが少なければ、ALUとAGUを別々に駆動しても問題ないのだが、その頻度があまり多いようだと、ALUとAGUがペアになって動く方が効率が良いことになる。
そもそも、先のフェッチ/デコード段の概要を説明する画像で、Dispatchから出てくるのは「Macro-Ops」であることに注意されたい。これはインテルの言うMacro-Opsと同じもので、要するに複数のMicro-Opsの組み合わせである。要するにフェッチの段階では
| x86 | ADD reg, Mem | メモリー上の値を加算するx86のADD命令 |
だったのがデコードの後では
| Micro-Op | load Mem, reg1 | reg1にMemの内容をloadするMicro Op |
| add reg, reg1 | regにreg1の内容を加算するMicro Op |
に変化し、これがDispatchを出るときには、以下のようにまとめられるわけだ。
| Micro-Op | load&add reg, reg1, Mem | 上の2つのMicro OpをまとめたMacro Op |
今まではスケジューラーの中で、このMacro-Opをもう一度ほぐしてALUとAGUに命令を投入していた形だが、そうであれば最初からほぐさずにスケジューラーでは1つのMacro Opとしてスケジューリングを行ない、それを発行する段階で2つに分離した方が効率が良いと判断されたようだ。このあたりはK7→K8の構造の推移に非常に近い。
下の画像は10 issue per cycleとあるが、これはStore Data×2が図には入っていないためだ。
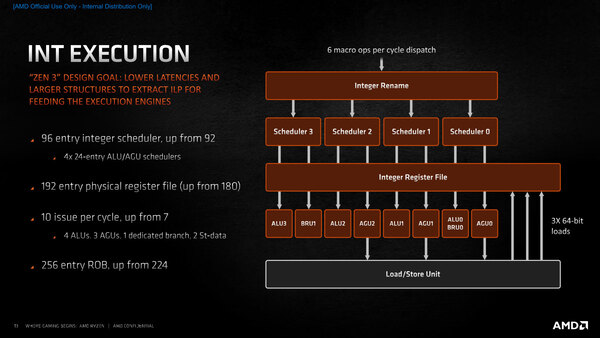
整数演算の仕組み。AVX命令を実行しながら並行してレジスターの内容の保存が可能になった。したがって、スループットは0.5だったのが1になったことになる
実際にはStore Dataの作業はロード/ストアーユニット側なのでここに計上するのは間違っているのかもしれないが、整数演算系で1サイクルあたり2つのストアーが可能(従来は1つ)というのは、特にメモリーに書き出しが多いアプリケーションでは性能向上につながることになる。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ













