




サポートされる命令は極小
プログラムも独自仕様
下の画像がTSPでサポートされる命令のすべてである。サポートされる命令はご覧の通り非常に少ない。だからこそ個々のTileを小さくまとめられるという話でもあると思うが。
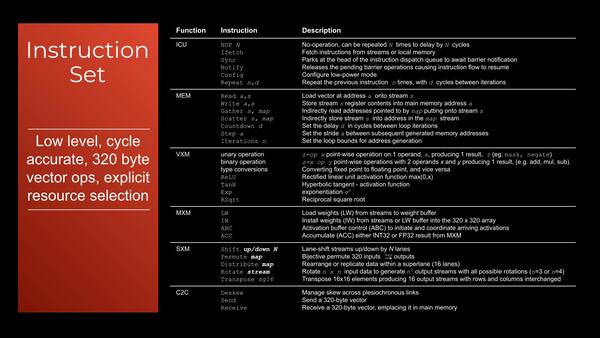
TSPでサポートされる命令。核となるのはVXMで、MXMなどもう完全にActivationとWeightしかサポートしていないシンプル振りである。ICUは本当にフロー制御のみなのがわかる
こういう特異な構成なので、プログラムも当然独自のものが必要となる。そもそもStreamを前提としているあたりで、通常のプログラミングモデルがまったく利用できないのは当たり前ではある。

独自仕様のプログラム。Map-Reduceはクラウドなどのスケールアウト環境で、多数のマシンで分散処理して、最終的にその結果を集約するプログラムであるが、それに似ているというのもわかるようなわからないような感じだ
もちろんGroqからはソフトウェアフレームワークというか、ソフトウェアスタックが提供されるとしているが、現状まだ十分にそろってるとは言い難いように思える。このあたりは今後の課題だろう。
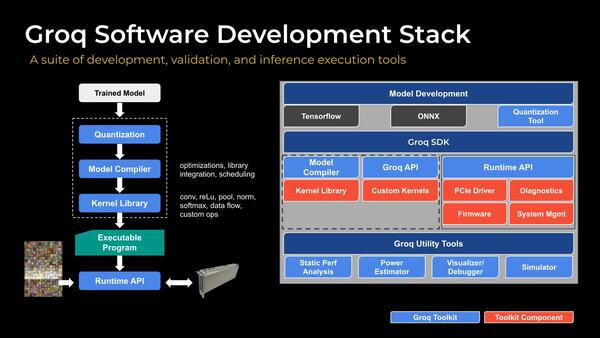
フレームワークとしてTensorflowと、ランタイムとしてONNXをサポートするとしているが、まだKernel LibraryやPCIe Driverなどは用意が間に合ってない模様。このあたりは徐々に提供予定なのだろう
インテルのHabana GOYAやNVIDIAのV100を
はるかに上回る圧倒的性能
このGroqのTSPが、以前から話題になっていたのはその性能の高さである。下の画像は、縦軸が応答時間(Latency)、横軸が毎秒の画像処理枚数である。テストそのものはResNet-50での結果であるが、圧倒的に高い数字を叩き出しているのがわかる。
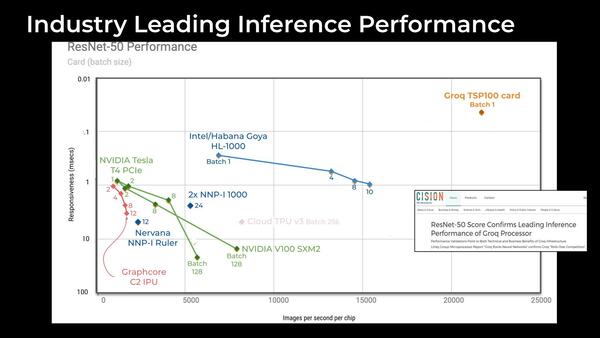
右上なほど性能が高いことになる
連載575回で、インテルが買収したNervana Systemsのリソースを全部捨てて、代わりにHabana Labsを買収しなおしてこちらを中核に据えたという話をしたが、そのHabana LabsのGOYAと比較しても性能は圧倒的である。
今年1月にMicroProcessor ReportがGroqのTSPを報じた際の数字で言えば、NVIDIAのV100が1.5GHz駆動で250TOPSとされるのに対し、TSPは1GHz駆動で820TOPSの性能になるとされていた。
実際上の画像でもわかるが、V100ではResNet-50での処理性能は最大でも7907枚/秒、GOYAでも1万5453枚/秒なのに対し、TSPは2万400枚/秒に達するとしている。
ちなみにここまでのスライドは、今年4月に開催されたLinley Processor Conferenceで発表されたもので、まだA0シリコンということもあって動作周波数は控えめ(前述のダイ写真では900MHzで750TOPSとされる)だったが、その後改良を重ねたようで、現在は公式に1.25GHzで1PetaOPS/秒、FP16で250TFLOPSという処理性能に引き上げられている。
Groqのメリットは、外部にメモリーを置かないで内蔵SRAMだけでカバーすることで、220MBという相対的に大容量のメモリー容量と、80TB/秒という強烈なメモリー帯域を両立できたことである。もっともその代償が268億個のトランジスタと725mm2という巨大なダイサイズになる。
ただ、それこそHabanaのGAUDIなどと異なり外部にHBM2を搭載したりしないし、14nmを使って725mm2なので、同じ性能で良ければ7nmに移行すればダイサイズは半分近くに抑えられるだろう。
もっとも、AI業界はだいたいダイサイズを縮めずに、その分演算ユニットとメモリー容量を増やす方向に走りがちである。したがって、仮に7nmに移行すると500MB弱のオンチップSRAMと、40本のSuperLaneを持ち、2Peta OPS/秒の性能を持つ製品が登場しそうではある。
4月以降のGroqは、6月に開催されたISCA(International Symposium on Computer Architecture)でTSPの内部構造に関して論文を発表したくらいであまり動きがない。
ただ今年9月末~10月にかけて開催される2020年のAI Hardware Summitに、再びゴールドスポンサーとして参加しており、なにかしらの話がここで出てくるものと期待されている。
また今年10月末に開催されるLinley Fall Processor Conference 2020でも、“Delivering Machine Learning at Scale”というタイトルの講演が用意されており、ここでもう少し細かい話が出てくるかもしれない。
AI向けチップというのは、たとえInference(推論)向けであっても、やっぱりお化けのようなチップになるという一つの例であろう。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 -
第873回
PC
「銅配線はまだ重要か? 答えはYesだ」 NVIDIA CEOジェンスンが語った2028年ロードマップとNVLink 8の衝撃 - この連載の一覧へ










とBTO PCならではの特注PCパーツに大興奮")
























ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












