




複数のTileをまたぐパイプライン処理となる
「SuperLane」
AIの推論に使う処理で言えば、まずConvolutionを行ない、次にActivationをして、最後に結果を格納する形になるが、そのためにまず最初にFP/INTでの演算を20Tileで同時に処理し、次のTileで必要ならActivation(SXM)をした後に、次のTile(MEM)に引き渡してメモリーへの書き出しを行なう。
もう少し個々のTileの詳細をまとめたのが下の画像である。各々のTileは16wayのINT/SIMDエンジンと、Tile間のOn-Chip NetworkのI/Fを持っている。
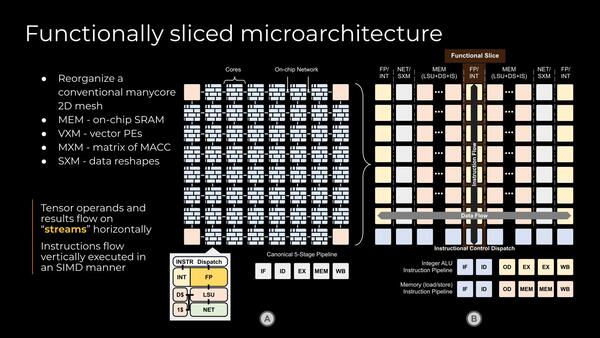
各々のTileは比較的シンプルな5段のIn-Orderパイプライン。もちろんスーパースカラーなども必要ないので、非常にシンプルである
この図で言えば、左側の8×8のTileで、縦方向の8つには原則として同じ命令が与えられ、データを自分の左のTileから取り込み、処理結果を右方向のTileに流すという形で動作することになる。
この結果として、命令処理は複数のTileをまたぐ形でのパイプライン処理になるというのが下の画像である。各々のTileに対してトータルで144の命令キューが用意されており、それぞれのTileに対しての必要な命令を割り当てる格好になっている。
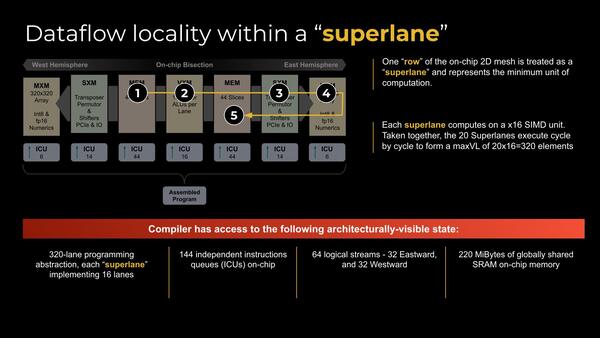
命令は複数のTileをまたぐパイプライン処理になる。同社はこれをSuperLaneと称する。ちなみにWest Hemisphere(西半球)とEast Hamisphere(東半球)は次の写真を参照
さて、西や東という用語が出てくる理由だが、TSPの内部構造は下の画像のような格好になっている。中央に合計220MBのSRAM(左右それぞれ44バンクで110MBづつなので、1バンクあたり2.5MB)がおかれ、その間に共通のVXM(ベクトル演算モジュール)が用意される。

TSPの内部構造。ちなみにダイサイズはおおよそ725平方mmとされる。これだけSRAMを搭載すれば当然だろう。製造プロセスは14nm CMOS。ファウンダリーはGlobalFoundriesとのことで、14LPPあたりであろう
SRAMの外にはまずSXM(スカラー演算ユニット:Activationなどに向けた特殊関数を提供する)がおかれ、さらにその外には2つのMXM(Matrix of MACC:MAC演算ユニット)が配される。このMXMは全部で10万2400の「重み」(畳み込み演算をする際の係数)を格納できる仕組みになっている。
1つ前の画像(SuperLane)の1~5の番号をもう一度見直すとわかりやすい。まず西側のメモリーからデータを取り出し、中央のVXMでベクトル演算を行ない、次いでSXMで必要に応じてシフト演算などを実行、MXMでActivationを経て、最後にそれを東側のメモリーに格納するという流れである。
もっともこれ、逆に東側のメモリーから取り込んで最終的に西側に格納するというストリームもありそうではあるが。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 -
第873回
PC
「銅配線はまだ重要か? 答えはYesだ」 NVIDIA CEOジェンスンが語った2028年ロードマップとNVLink 8の衝撃 - この連載の一覧へ










とBTO PCならではの特注PCパーツに大興奮")
























ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












