




複数のTileをまたぐパイプライン処理となる
「SuperLane」
AIの推論に使う処理で言えば、まずConvolutionを行ない、次にActivationをして、最後に結果を格納する形になるが、そのためにまず最初にFP/INTでの演算を20Tileで同時に処理し、次のTileで必要ならActivation(SXM)をした後に、次のTile(MEM)に引き渡してメモリーへの書き出しを行なう。
もう少し個々のTileの詳細をまとめたのが下の画像である。各々のTileは16wayのINT/SIMDエンジンと、Tile間のOn-Chip NetworkのI/Fを持っている。
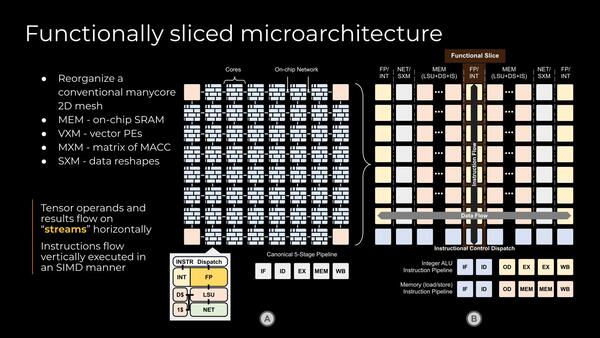
各々のTileは比較的シンプルな5段のIn-Orderパイプライン。もちろんスーパースカラーなども必要ないので、非常にシンプルである
この図で言えば、左側の8×8のTileで、縦方向の8つには原則として同じ命令が与えられ、データを自分の左のTileから取り込み、処理結果を右方向のTileに流すという形で動作することになる。
この結果として、命令処理は複数のTileをまたぐ形でのパイプライン処理になるというのが下の画像である。各々のTileに対してトータルで144の命令キューが用意されており、それぞれのTileに対しての必要な命令を割り当てる格好になっている。
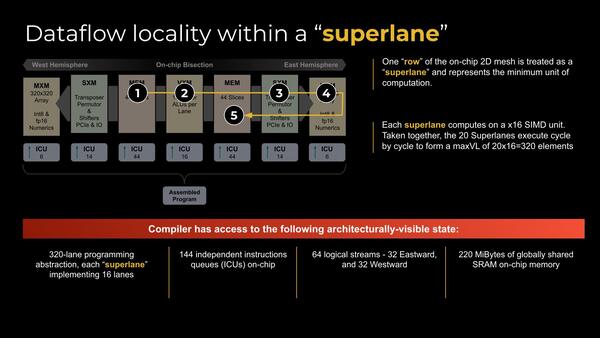
命令は複数のTileをまたぐパイプライン処理になる。同社はこれをSuperLaneと称する。ちなみにWest Hemisphere(西半球)とEast Hamisphere(東半球)は次の写真を参照
さて、西や東という用語が出てくる理由だが、TSPの内部構造は下の画像のような格好になっている。中央に合計220MBのSRAM(左右それぞれ44バンクで110MBづつなので、1バンクあたり2.5MB)がおかれ、その間に共通のVXM(ベクトル演算モジュール)が用意される。

TSPの内部構造。ちなみにダイサイズはおおよそ725平方mmとされる。これだけSRAMを搭載すれば当然だろう。製造プロセスは14nm CMOS。ファウンダリーはGlobalFoundriesとのことで、14LPPあたりであろう
SRAMの外にはまずSXM(スカラー演算ユニット:Activationなどに向けた特殊関数を提供する)がおかれ、さらにその外には2つのMXM(Matrix of MACC:MAC演算ユニット)が配される。このMXMは全部で10万2400の「重み」(畳み込み演算をする際の係数)を格納できる仕組みになっている。
1つ前の画像(SuperLane)の1~5の番号をもう一度見直すとわかりやすい。まず西側のメモリーからデータを取り出し、中央のVXMでベクトル演算を行ない、次いでSXMで必要に応じてシフト演算などを実行、MXMでActivationを経て、最後にそれを東側のメモリーに格納するという流れである。
もっともこれ、逆に東側のメモリーから取り込んで最終的に西側に格納するというストリームもありそうではあるが。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ







































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")



























