



ロードマップでわかる!当世プロセッサー事情 第579回
Tiger Lakeの内蔵GPU「Xe LP」は前世代のほぼ2倍の性能/消費電力比を実現 インテル GPUロードマップ
2020年09月07日 12時00分更新

GPUは1チップ構成だが
GPGPU用途ではマルチチップ構成を想定
Media Sliceは動画のエンコード/デコードを担当するユニットだが、コーデックをダブル搭載できるとか、SFCを複数実装できるあたりが拡張機能となる。後で出てくるXe SG1は、このMedia Sliceが重要なポイントだという説明であった。

とはいえ無尽蔵に、例えばMFXやSFCを3つや4つに増やすことはできない模様。そういう場合はMedia Sliceそのものを増やす形で対応すると思われる
Memory Fabricは、これもさまざまなオプションが用意されている。通常はまず3次キャッシュが使われるが、HPC向けにはここにRambo Cacheが充てられることになるようだ。
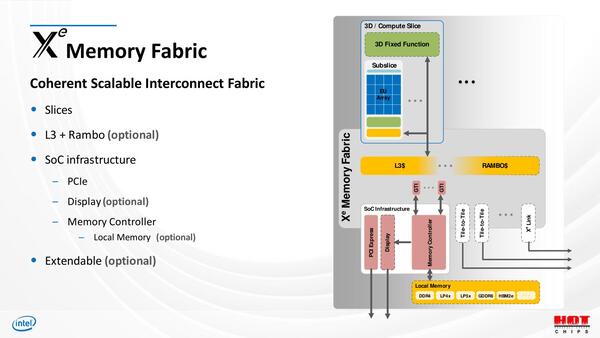
Memory Fabricの説明。SoCからPonte Vecchioまで、基本構造は同じとなると、当然こういうなんでもありの構成になる。ただ現実問題としてSoCとPonte Vecchioでは扱うデータ量が桁違いなので、内部のインターコネクトも当然帯域が大きく変わるわけで、実際には基本的な設計図が同じだけで、実装はだいぶ違ったものになっていると思われる
PCI Expressは当然として、ここにLocal MemoryやXe Link/Tile-to-Tile I/F、さらにDisplay Unitなどがオプションで追加される形になる。
ちなみにスケーリングであるが、ことGPU(つまりグラフィック向け)に関して言えば、昨今ではマルチチップ構成はあまり好まれない。これは連載515回でNAVIのRB(Render Backend)の説明でも触れたが、Deferred Renderingを多用する場合、多数のEUから同一のメモリーエリアに対してアクセスが頻発することになる。
NAVIの場合はこれを1次キャッシュでカバーしているわけだが、仮にマルチチップになるとRBがアクセスしようとしたメモリー(の内容を保存しているキャッシュ)が別のタイルにあるかもしれない。そうすると、アクセスが猛烈に遅くなる。
これもあってマルチチップの技法はAMD/NVIDIAともに採用しておらず、インテルもやはりXe LPやXe HPGでは1チップ構成で済ますようだ。
一方でGPGPU的に利用されるXe HP/Xe HPCの場合は並列度を上げても有効に使いやすく、またRBみたいなニーズも薄いことから、マルチチップ構成を積極的に追及する方向のようで、EMIBを利用した最大4Tileのパッケージや、マルチパッケージの接続が想定されている。

連載569回で説明した、Raja氏が手に持っているものが、このTile方式で接続されたものと思われる

NVIDIAのNVLINKやAMDのInfinityFabricに相当するのがこちら。XeLinkという名前になる模様。ちなみにここでは6パッケージが接続されているが、これが最大かどうかは不明
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























