




NVIDIA V100の14%増しの学習性能を誇る
GAUDIことHL 2000
一方のメインとなるのがGAUDIことHL 2000である。こちらも詳細は明らかになっていないが、ぱっと見GOYAによく似た構成である。

GAUDIことHL 2000。構成はSpring Crestと同じく、メインのチップに4つのHBMをシリコン・インターポーザーで接続する形態
大きく異なるのはHBM2と、あと目立たないがRoCE対応の10×100Gイーサネットポートである。
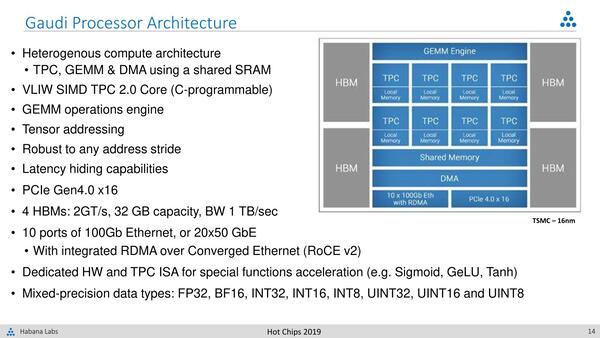
GAUDIの概要。個々のTPCの中身が公開されていないので、なんともいいにくいのだが
肝心の性能はHotChipsの時点では一切未公開であったが、MicroProcessor Reportに記事を寄せる形で学習性能はNVIDIA V100の14%増し、性能/消費電力比はT4の2倍、V100の2.5倍といった数字を出している。
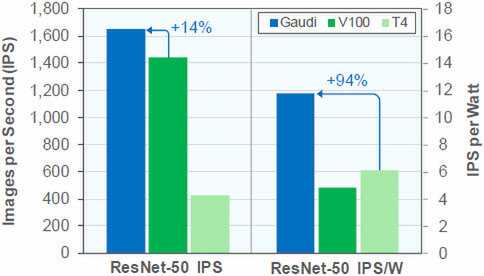
ちなみにこれはシミュレーションを利用しての推定値
また、チップの個数を並べた場合の実効性能が落ちにくいのも特徴であり、結果として多数のプロセッサーを利用した場合の性能はV100比で4倍近くなるとされる。
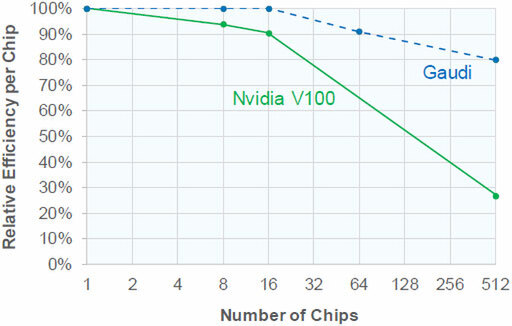
こちらもGAUDIについてはシミュレーションを利用しての推定値。チップの個数を並べた場合の実効性能が落ちにくいことを示している
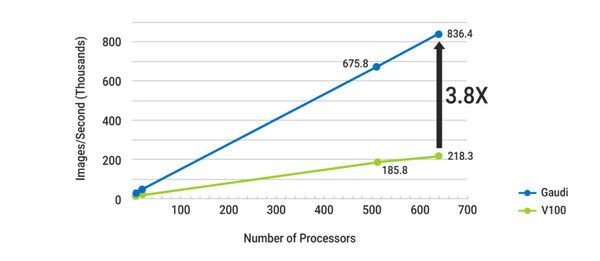
多数のプロセッサーを利用した場合の性能はV100比で4倍近くなる。実はこれ、単に上の画像の実効性能にチップの数を掛け合わした結果だけでなく、ネットワーク性能も関係してくる。ちなみに縦軸は数千イメージ/秒であることに注意
この性能については後述するとして、もう1つ大きな特徴がRoCEへの対応である。RoCEとはRDMA over Converged Ethernetの略であり、そのRDMAというのはRemote DMAの意味である。
もともとInfiniBandという「インテルが2度も捨てた」ネットワーク規格があり(というか今もある)、現在はNVIDIA傘下にあるイスラエルのMellanox Technologiesが主要なベンダーであるが、そのInfiniBand向けにRDMAというプロトコルが規定された。
これはネットワーク経由のデータ転送を、一切CPUを介さずにネットワークアダプターだけで済ませてしまうというもので、CPUから見るとネットワークに対して転送命令を出すだけでいつの間にかメモリーに結果が入ってる、というわけでRemote DMAと称したわけだ。
このRDMAそのものはInfiniBand向けのものだが、これをTCP/IPの世界に持ち込んだのがRoCEである。ちなみに、他にiWARP:Internet Wide Area RDMA Protocolと呼ばれているよく似た別の規格もある。
プロトロルの話はおいておくとして、このRoCEはやはりMellanoxからアダプターが出ているのだが、GAUDIではこれを全部オンチップに搭載してしまい、しかも100GbE×10も搭載されている。
同じことを通常のイーサネットカードでやることは不可能である。なぜならI/Fの帯域が足りないためだ。100Gイーサネット(=100Gbpsの双方向)をサポートするためには、PCIe Gen3×16、ないしPCIe Gen4×8のI/Fが必要である。
これを10個ということは、チップにPCIe Gen3×160、あるいはPCIe Gen4×80のレーンが要求される。もちろんこんなI/Fは搭載できないので、スピードを落とすかイーサネットの数を減らすことになるが、そうなると特にスケーラビリティーの点で見劣りすることになる。
またPCI Expressを挟むとそれだけでLatencyが増えることになる。Photo22でV100が、数が増えると急速に性能が劣化する理由はこのネットワークにあり、この点でGAUDIにはかなりのアドバンテージがある。
さて、先の3枚の画像はあくまでもシミュレーションを使った推定であるが、その後実機を使ってMLPerfが非公開で実施され、ここでGAUDIはNVIDIAのT4やV100だけでなく、Spring Crestをもぶっちぎる性能だったらしい。

Back-to-Back(送り出したパケットをそのまま送り返してもらって受け取る)のレイテンシーが300nsというのは、おそろしく高速である。300nsというのは、やや遅めのメモリーにランダムアクセスする場合と大して変わらないレイテンシーだからだ
加えて言えば、GAUDIの100G×10 RoCEはインテルにとって福音であった。インテルは2019年7月、OmniPath Fabricという独自のクラスター向けインターコネクトの開発から撤退した。
OmniPath Fabcicは2016年に、まず100Gbpsのものが実用化され出荷もなされていたが、この後継である200Gbpsの製品の開発がうまくいかなかったらしい。
この直前の2019年6月、インテルはBarefoot Networkというイーサネット・スイッチの会社を買収しており、今後はイーサネットベースでクラスターを構築する方向に舵を切ったわけだが、このBarefootのスイッチとGAUDIの100G RoCEは非常に相性が良い。
Spring Crestの場合はPCIe経由で外部にイーサネット・アダプターを取り付けることになるが、構成から言って100Gイーサネット×2が精一杯であり、スケーラビリティーはずっと劣ることになる。
この2つの理由からインテルは4億ドルを捨てて、改めてHanaba Labsの製品を同社のAI戦略の主軸に置いたわけだ。ちなみにHabana Labsの買収金額はおおよそ20億ドルである。
Hotchipsでの発表からわずか半年で、見事に明暗が分かれた2つのチップというか、アーキテクチャーだったわけだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ











の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")





























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






















