




Lake Crestの後継となる
深層学習用プロセッサーSpring Crest
さてそのSpring CrestことNNP-Tは、2つのTensor Coreを組み合わせたTensor Core Cluster(TPC)を24個搭載。PCI ExpressもGen4としたほか、メモリーを2.5MBに増やしている。製造プロセスはTSMCの16FF+を利用、ダイサイズは680mm2とされる。
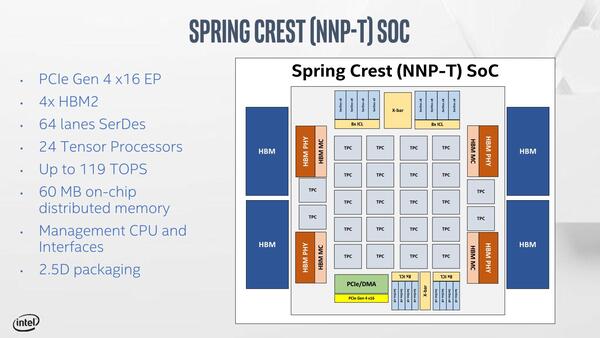
Spring CrestことNNP-Tの概要。実質的にはコアの数がLake Crestの4倍になった計算である

HSIOはHigh Speed I/Oで、外部リンクをこれでまかなうと思われる
下の画像はTPCの内部構造で、2つのTensor Processorとローカルメモリー、Convolution Engineなどを共有する構造になっている。
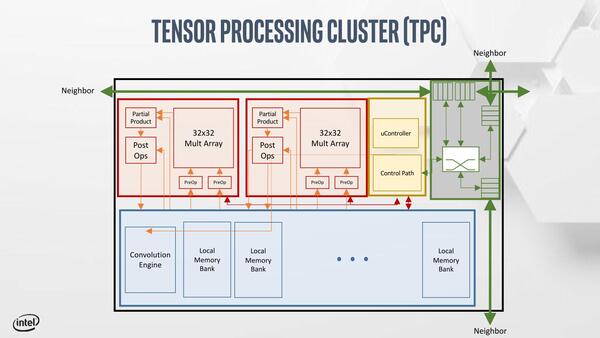
TPCの内部構造。Local Memory Blockは複数バンクに分割されているようだが、サイズなどは不明
個々のTensor ProcessorはBFloat16の演算ユニットを32×32個アレイ状に配した構成で、1サイクルあたり2048演算(乗算+加算)が可能である。

Tensor Processorの構成。BFloat16のユニットを2つ組み合わせてFP32もサポートできる模様。当然その場合性能は半減する
1TPCあたりなら1サイクルあたり4096演算。これが24個で、1.1GHz駆動ということで 1.1GHz×24×4096=108.1344TOPsとなる。
さらに、TPCの共有部にはConvolution Engineが専用に搭載されており、これは上の画像のCompute Unitとは並行して稼働するようなので、これの処理分も含めると119TOpsという数字になるのだと思われる。
なおそれぞれのTPCは2Dメッシュ構成での接続になっており、すべての周辺機器やI/Oに均一にアクセス可能になっている。
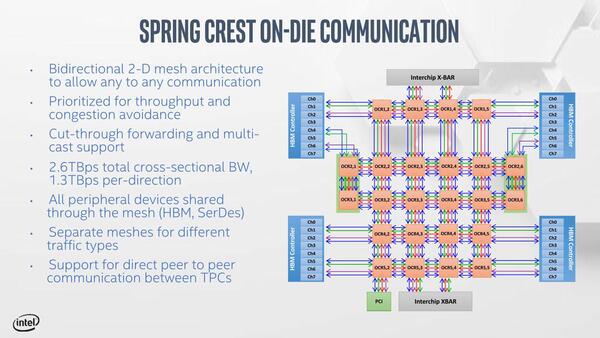
ここでRing Busではなく本当にBi-DirectionalなLinkを使っているあたりで、インテルではなくNervanaの設計だなという気がする
またスケーラビリティーにも配慮されており、最大1024ノードまでの接続が可能とされる。ちなみに性能の一端も公開された。

これは、3枚目の画像に出てくるような評価ボード8枚を1つのシャーシに入れることを前提にした模式図と思われる。ちなみに1つのシャーシ内に8ノードで、これ全体だと32ノードという計算になると思われる

NNP-Tの性能。サイズに応じて学習の効率が変わるが、小さくても大きくてもなかなか性能が出ないので、HBMの容量をにらみながらサイズを決める必要があるという話。ちなみにピークでも57.4%というのは、もう少しなんとかならなかったものか?

Convolutionの効率。こちらは専用ユニットを設けていることもあってか、どのケースでもそれなりに効率が高い
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 -
第873回
PC
「銅配線はまだ重要か? 答えはYesだ」 NVIDIA CEOジェンスンが語った2028年ロードマップとNVLink 8の衝撃 - この連載の一覧へ











&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")



















ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












