




非線形関数で得たデータのサイズを縮める
「サブサンプリング」
最後がサブサンプリングである。Feature Mapで特徴を抽出し、非線形関数でそれを強調した後、そのままのサイズで次の処理に移るとデータ量が大きすぎる、という問題がある。そこで、特徴を生かしたままサイズを縮めて扱いやすくするのがこのサブサンプリングである。
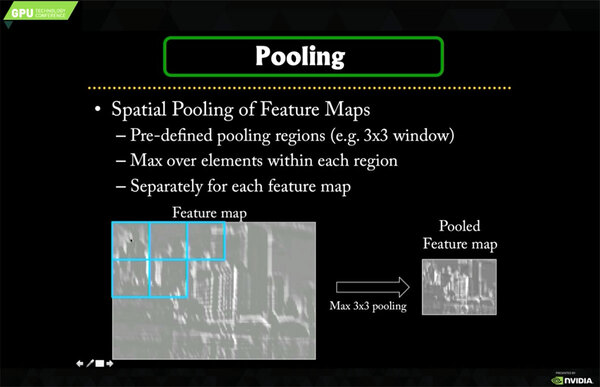
サイズを縮めるサブサンプリング。ここではPoolingとなっているが、意味は同じであ
これも先の畳み込み同様、小さいサイズ単位(上の画像なら3×3)で行なうのだが、3×3の中で一番大きな値をそのまま出力するMax Poolingや、3×3の全体の値を平均化するAvg Poolingなどがある。
計算の手間で言えばMax Poolingの方が若干楽ではあるのだが、最近はMax PoolingとAvg Poolingのどちらも一発で計算できるアクセラレーターが増えてきているあたり、用途に応じてここは調整しているようだ。
以上で、畳み込みの説明が完了である。前回のAlexNetの場合、層の数が増えるにつれ、ImageあるいはFeature Mapのサイズは小さくなっているが、なにしろ5層構造だし、そもそもの画像サイズが大きいから計算には時間がかかるのが理解できるだろう。
畳み込みを繰り返して精度を上げる
余談ではあるが、第1層~第5層それぞれの入力画像とフィルター画像を並べたのが下の画像である。

第1層~第5層それぞれの入力画像とフィルター画像を並べたもの。出典はMatthew D. Zeiler氏とこのセッションの講師であるRob Fergus氏による“Visualizing and Understanding Convolutional Networks”という論文。氏のセッションの中でこの論文を引用して説明があったので、こちらでも使わせていただいた
第1層~第3層までは、全体の一部が切り取られている格好なので、なんの画像なのかさっぱりわからないが、サブサンプリングによってだんだん画像の全体像が見えてくるようになっている。
言ってみれば、目的とする識別に必要な画像の特徴を抽出かつ小型化することで、続く全結合層で判断をしやすくするのがこの5層にわたる畳み込み層の目的、ということがおわかりいただけるだろう。
画像を識別させる
「全結合」
さて、続く全結合層だが、これは最終的に画像の識別を行なわせるための準備である。冒頭で触れたLeCun氏のネットワークの場合、最終的には0~9という数字を認識するのが目的である。
そこで0~9という10個の出力ユニットを用意し、例えば“3”であれば“3”の出力ユニットのみ1、他は0になるような仕組みにすればいい。実際はそこまでうまくいかず、3の確率が75%、8の確率が15%、3と9の確率がそれぞれ5%といった形での出力になるのだが、そうした確率が出てくるだけマシである。
AlexNetの場合は1000種類の識別が要求されているので、出力ユニットもやはり1000個になる。ただ、いきなり1000個にはできないので、4096個の層を2回挟んでの出力になる。
ちなみに全結合だが、これは名前の通りすべての値を、係数をかけて足し合わせるものだ。下図は簡単化するために、入力を4×4の16、出力を8にしたが、この場合各々の出力に対して16回の乗算と足し算を行う形である。
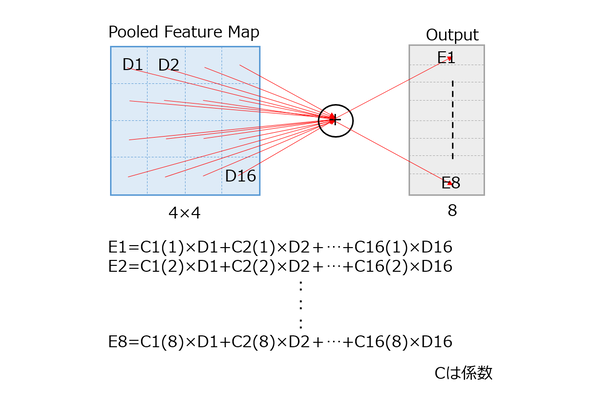
全結合(入力を4×4の16、出力を8にした場合)
ここで係数は出力ごとに異なっている。つまり16×16の入力画像を8つに全結合するだけで、128回の乗算と加算が必要になるわけだ。
AlexNetの場合、最終的には13×13(ピクセル)×256(フィルター数)の出力を4096個のアウトプットに出力するのに1億7720万9344回の乗算と加算、次いで4096個を4096個に再び全結合するのに1677万7216回の乗算と加算、最後これを1000個の出力ボックスにまとめるのに409万6000回の乗算と加算が必要になる。
やってることは乗算と加算だけなのだが、なにしろその回数がシャレにならないほど多いのがおわかりいただけるだろうか?
ラフに言っても1枚の処理に10億回以上の乗算と加算が必要で、仮にメモリーアクセスのレイテンシーなどが一切ないとしても、1.4GHzのCPUをフル駆動させて1枚あたり1秒で処理できるかどうか、というあたりである。
ちなみにこれは「たった1枚の画像」を処理する際の時間である。推論、つまり入力画像からその内容を判断するのはこの時間で済むが、学習のフェーズではこの百万倍の時間が必要になる。実際にはパラメーターを調整しながら何度も繰り返して投入することになるので、数百万倍の可能性もある。このあたりの数字の大きさの感覚をご理解いただければ、説明としては十分である。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ







































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")



























