最新パーツ性能チェック 第287回
クリエイティブ系ソフトで「Ryzen Threadripper 3990X」の64コア/128スレッドをフルに使えるか検証
2020年03月18日 11時00分更新

Ryzen Threadripper 3990Xのパワーが活きない場合とは
もうひとつCG系アプリとして「Houdini Apprentice」もチェックしてみよう。このアプリの用途のひとつに、粒子の挙動を物理演算でシミュレートするものがあるが、これは粒子の数が増えるほど計算負荷が高まる。演算にはCPUを使うのでRyzen Threadripper 3990Xはうってつけのソリューションに思える。
今回はXeon W-3175Xレビュー時に使用したプロジェクトを利用する。粒子のpoint数は49万弱、最初のフレームから120フレーム後の様子をプレビューさせた時間を内蔵パフォーマンスモニターを利用して計測した。
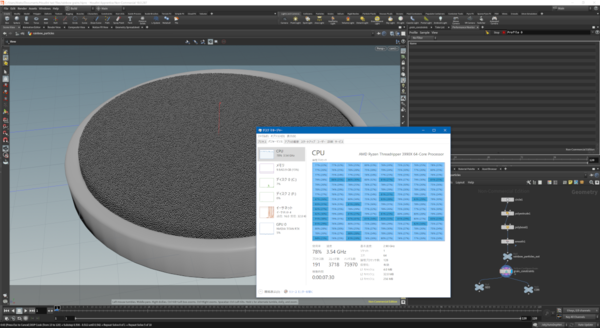
「Houdini Apprentice」におけるCPUの使われ方。プロセッサーグループの壁は越えているものの、各コアの負荷は70〜100%の間を変動する
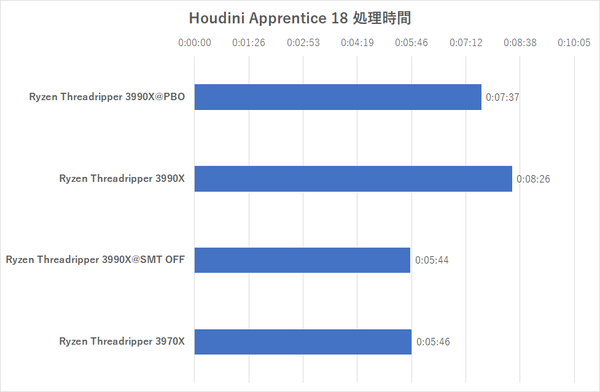
「Houdini Apprentice」のプレビュー生成時間(秒)
Houdini Apprenticeでもプロセッサーグループの壁は越えてくれるが、128スレッドをフル活用しようとすると、むしろ遅くなる結果が出たことは興味深い。PBOを有効にしてOCすると処理時間が短縮されるが、それよりもSMTをオフにした方が早くなる。つまりプロセスを分割しすぎると逆にそれがオーバーヘッドになって、性能が下がってしまうことが示されている。
前回動画エンコード系代表として「Media Encoder 2020」を利用し、H.264の4Kのエンコードで検証したが、その際にプロセッサーグループ内の64スレッドでも使い切れず、同じソースで4つパラレルで書き出してようやく64スレッドをフルで使えると示した。
今回は「DaVinci Resolve Studio 16」で検証しよう。8KのRED RAW動画で構成された約2分半のシーケンスを準備し、それを1本の8K(7680×4320)動画に書き出す時間を計測する。ファイル形式とコーデックは定番のMP4&H.264に加え、MXF OP1a&DNxHR 444の2通りで検証した。
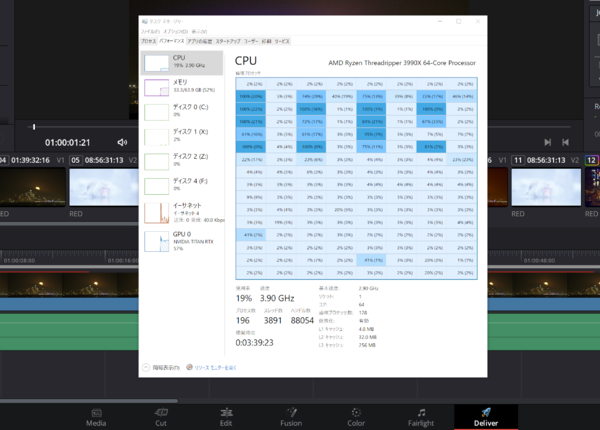
「DaVinci Resolve Studio 16」のエンコード処理中の模様。CPUの負荷は20コア前後にとどまっているが、GPUの負荷も相当高い点に注目
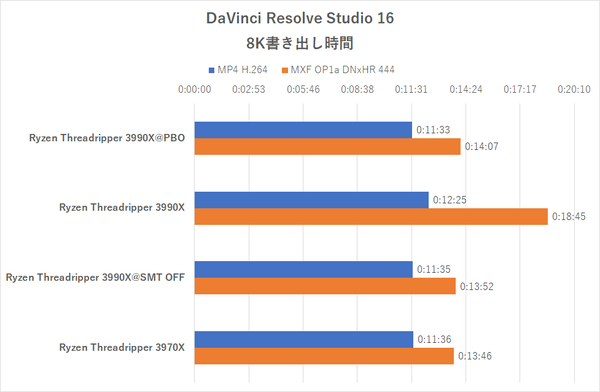
「DaVinci Resolve Studio 16」のエンコード時間
タスクマネージャーで観測できるCPU負荷はプロセッサーグループ0(ヒートマップの上半分)に集中しているものの、128コア全てにうっすらと負荷がかかっていることが確認できるが、これはカラーグレーディングやフィルター処理にGPUをかなり活用(タスクマネージャーのGPU負荷のグラフに注目)しているため。弱い負荷だけかかっているコアはGPU側に処理させるために使われているようだ。
つまりこの検証ではRyzen Threadripper 3990Xのパワーは有効活用できていない。SMT有効時のRyzen Threadripper 3990Xの方が遅いが、これもHoudini Apprenticeと同様にオーバーヘッドが足を引っ張っているからと考えられる。
もうひとつ動画エンコード系として「Handbrake」でも試してみた。再生時間約5分の4K動画をプリセットのプロファイル「Super HQ 1080p30 Surround」および「H.265 MKV 2160p60」を利用してそれぞれM4V/MKV形式に書き出す時間を計測した。
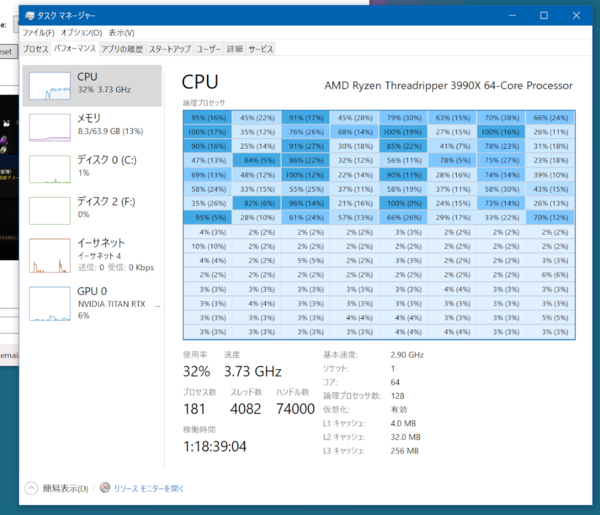
「Handbrake」でH.264エンコード中のCPUの様子。プロセッサーグループ内で処理が進む
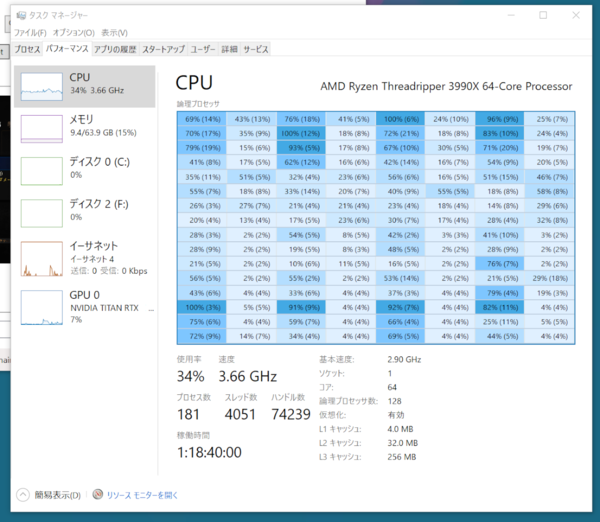
同じソースをH.265/MKVでエンコードする場合は、プロセッサーグループの壁を越えているように見える
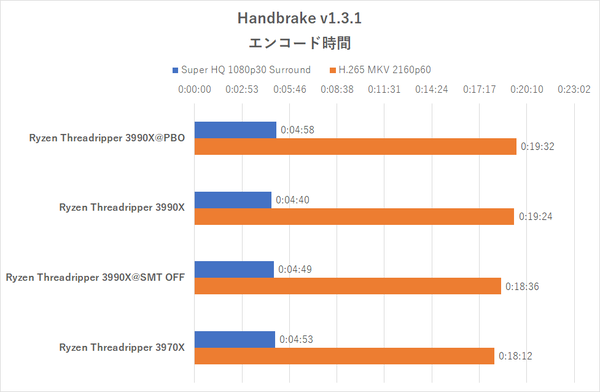
「Handbrake」によるエンコード時間
PBO有効時は熱の問題が発生するのか、Ryzen Threadripper 3990Xの定格時よりも若干遅くなっているが、定格時よりもSMTを無効にした時のほうが高速というのはDaVinci Resolve Studioと共通している。プロセッサーグループの壁を越えることのできたH.265のエンコード処理はさぞ高速か……と思いきや、Ryzen Threadripper 3990Xが3970Xより確実に速いとはいえない程度の差しかない。プロセッサーグループの壁を越えることができても、スレッドを128に分割する意義がなければ、高速化しないということだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第480回
自作PC
Radeon RX 7000シリーズが予定より早くFSR 4に対応、中堅GPUでもより鮮明でリアルな映像を実現! -
第479回
自作PC
Radeon RX 9070 GREレビュー! VRAM 12GBでRTX 5060 Ti 16GBに圧勝しRTX 5070に迫る -
第478回
自作PC
Ryzen 9 9950X3D2最速レビュー【後編】 デュアル3D V-Cacheのゲーム性能を詳しくチェック -
第477回
自作PC
Ryzen 9 9950X3D2最速レビュー デュアル3D V-Cacheで開発者・クリエイター向け最強CPUになった驚きの実力を解説 -
第476回
自作PC
ゲーム30本でCore Ultra 7 270K PlusとCore Ultra 5 250K Plusの性能テスト!9700Xや14700Kよりも優秀で、Intel BOTの恩恵も大きめ -
第475回
自作PC
Core Ultra 7 270K Plusは定格運用で285K超え!Core Ultra 5 250K Plusは265Kにほど近い性能 -
第474回
自作PC
Core Ultra X9 388H搭載ゲーミングPCの真価はバッテリー駆動時にアリ Ryzen AI 9 HX 370を圧倒した驚異の性能をご覧あれ -
第473回
デジタル
Ryzen 7 9800X3Dと9700Xはどっちが良いの?! WQHDゲーミングに最適なRadeon RX 9060 XT搭載PCの最強CPUはこれだ! -
第473回
自作PC
「Ryzen 7 9850X3D」速攻検証:クロックが400MHz上がった以上の価値を見いだせるか? -
第472回
sponsored
触ってわかった! Radeon RX 9070 XT最新ドライバーでFPSゲームが爆速&高画質に進化、ストレスフリーな快適体験へ -
第472回
自作PC
Core Ultraシリーズ3の最上位Core Ultra X9 388H搭載PCの性能やいかに?内蔵GPUのArc B390はマルチフレーム生成に対応 - この連載の一覧へ












