




AtomクラスのCPUでは珍しい
QoSを利用可能
次はデータパス回り。Load/Storeユニットはデュアル構成で、2つのSSEユニットのLoad/Saveを1サイクルで行なえることが目的と思われる。
Load/Storeユニットの帯域そのものは128bit幅である。L1 Data Cacheのレイテンシーは3サイクルでそれほど高速ではないが、これは性能と消費電力のバランスをとったものだろう。

L2 TLBが1024 entryと、これもCore並みに大きくなっているのも特徴。それだけ大量のメモリーを使うことが想定されているという話だろうか
L2がまた特徴的で、最大4コア共通で1.5~4.5MBという、やけに中途半端な容量で構成可能となっている。またL2に対してQoS(Quality of Service)を掛けられるほか、LLC(要するにL3)にもQoSが利用できる、としている。

QoSは、アクセスの優先順位や帯域保障を行なうメカニズムであるが、AtomクラスのCPUここれが入るのはかなり珍しい。おそらくネットワーク向けのSoCなどの構築に際して要望されたものだろう
Goldmont Plusより平均30%の性能向上
このTremontの性能だが、Goldmont Plusとの性能比較が下の画像だ。周波数をそろえた状況でのシングルスレッドでの性能改善率である。
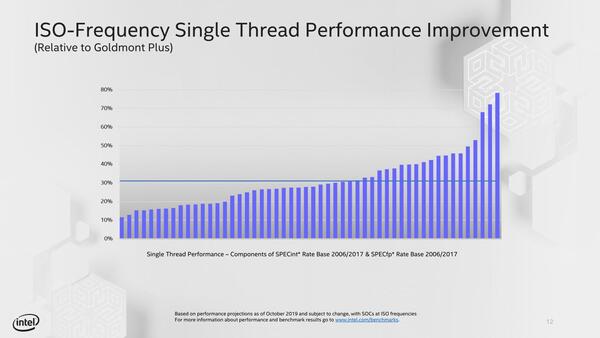
TremontとGoldmont Plusの性能比較。横軸はSPECint Rate Base/SPECfp Rate Baseに含まれる各テスト項目を、性能差が小さい順にならべたものの。最小で10%強、最大80%弱の向上があり、平均30%という話である
絶対性能としては相変わらずそれほど高いところは狙っていないのがわかる。そもそもここまで複雑化すると、14nm++で製造するとかなりダイが大きくなりそうで、10nm+での製造は必須である。
ただ、10nm+であまり動作周波数を引き上げると、消費電力が激増する。そこで、10nm+を使いつつ、それほど動作周波数を引き上げない(=消費電力も急増しない)美味しい範囲で、そこそこの性能を確保する、というのがTremontの設計目標のようだ。だから、動作周波数を引き上げると急速に美味しくない結果になるわけだ。
このTremont、まずはLakefieldに搭載され、2020年にマイクロソフトのSurface Neoに実装されて世の中に出てくるだろう。
ただその2020年以降は、現在のGemini Lakeの後継製品がこのTremontベースで投入される可能性はないわけではないと思う。ただタイムライン的には2020年中かどうかは疑わしい。2021年送りかもしれない。
仮に登場したら、それほど急激に性能が上がるわけではないが、現状のGemini Lakeよりは多少マシな性能は期待できそうだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ



















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")


































