




2次元パターンの配線を作れない
SAQP(Self-Aligned Quadruple patterning)
配線をやり直すというのはどういうことか。下図は簡単な模式図だが、例えば左端にあるFinFETのドレイン(A)を、右端のFinFETのソース(B)につなぎたいと思ったとする。
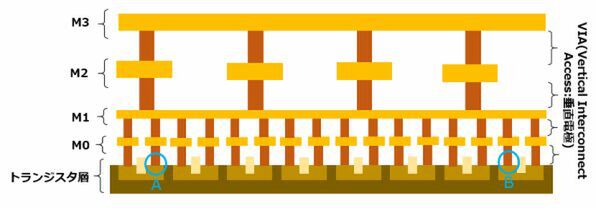
左端にあるFinFETのドレイン(A)を、右端のFinFETのソース(B)につなぎたい
従来なら、可能であればM0/M1を使って接続する形になっていたわけだ。
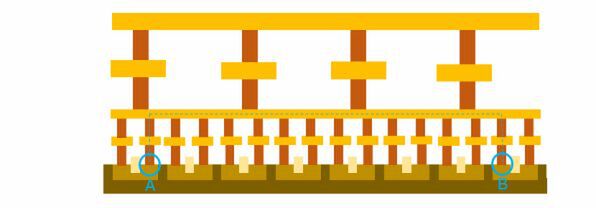
M0/M1を使って接続するのが従来の配線
これを、より抵抗の少ないM2以上を使って接続するようにして、M0/M1の利用頻度を減らそうということだ。この技法はVIA Pillarと呼ばれている。
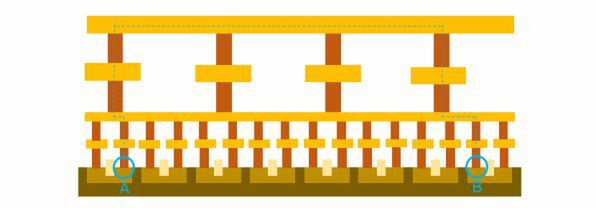
より抵抗の少ないM2以上を使って、M0/M1の利用頻度を減らす
これは、言うは簡単だが実際にやるのはかなり困難である。まず、そもそもM2以上の配線層が遊んでいるならば簡単だが、実際にはそんなことはなくギッチギチに詰まっているわけで、これを無理やりどけてM0/M1を使っていた配線層をM2以上に持ち上げるのは、かなりの難易度である。
場合によってはM10までで済まず、M11やM12まで必要になるかもしれない。この時点でまず既存の配線層がそのまま使えないことになる。
これに輪をかけて難しくしているのがSAQPである。これもちょうどインテルのスライドに説明があったので使わせていただくと、配線層(トランジスタ層でもそうだが)を構築する場合、SADPとLELEという2種類の方式がある。
SADPは下の画像の左側で、まずマスクから露光してパターンを作った後で、そこに薄膜(厚さ1nm程度)を構築、ついで余分な部分を抜くことで、もともとのパターンの半分の間隔でパターンを作れる。
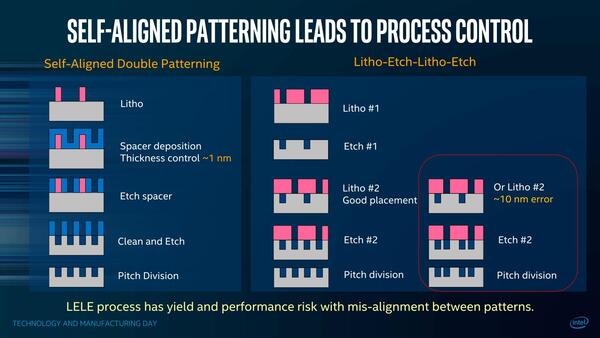
左側がSADP。右端の話は、LELEはマスクの重ね合わせミスがあると、生成されるパターンに異常が生じやすいというものだ
SAQPはこれを2回繰り返すことで、元のパターンの1/4の間隔でのパターン構築ができる。対してLELEは露光→エッチングをした後で、その上に別のパターンを再び露光→エッチングすることで、細かいパターンを作りこむというものだ。いわゆるダブルパターニングといえば、普通はLELEを指すことが多い。
問題は、SADPでもSAQPでもそうだが、2次元パターンは作れないことだ。下図は冒頭のスライドの左側の立体を抜き出したものだ。気を付けて見直してほしいのだが、黄色や赤の配線は、よく見ると1次元配線になっていることがわかる。

冒頭のスライドの左側の立体を抜き出したもの
先の模式図を上から見た場合のトランジスタ層とM0/M1層は、下図のような格好になっている。あとは必要なところにVIAを打って回路をつなげるという形だ。
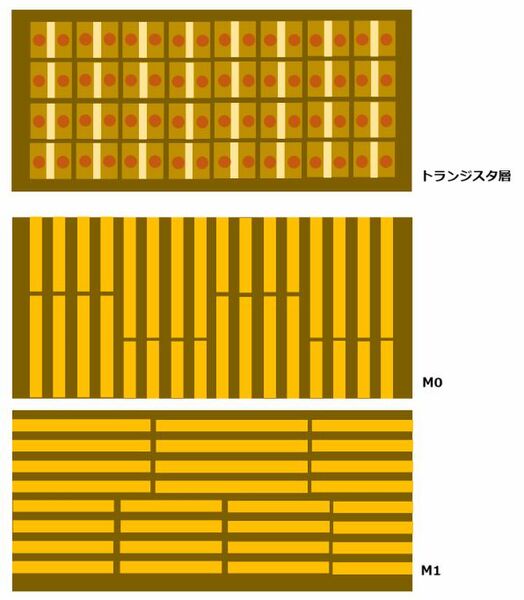
上から見た場合のトランジスタ層とM0/M1層
さてこの図でM0/M1の配線が4本一組なのは、もちろん意味があってのことである。SADPなら2組、SAQPなら4組単位でしか配線を行なえない、というのがSADP/SAQPの大きな欠点である。当たり前の話で、SAQPは下図のように構築するので、4つ一組にしかなりえない。
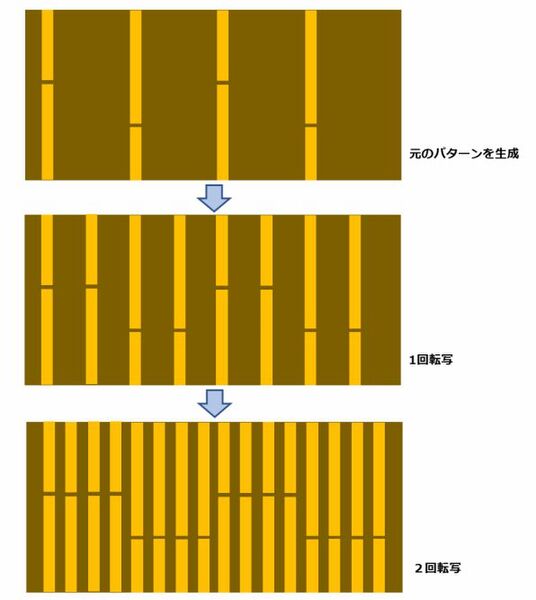
SAQPは4つ一組にしかなりえない
また図で言えば、横方向に伸びるパターンは、転写したパターンとくっついてしまうため原理的に作れない。もちろん端から端まで貫通するようなパターンならば生成できるが、M0/M1でそうしたパターンは普通使われない。
こうなると、M0/M1経由でM2以上に配線を逃がす作業そのものが強烈に難しくなる。あるトランジスタの配線を迂回しようとすると、そこから始まる4つ分のトランジスタの配線を全部同じように迂回させなければいけないわけで、設計が極めて困難なのは火を見るより明らかである。
ちなみにLELEなら2次元パターンも構築できるのだが、実はLELE程度ではコストの増加は無視してもピッチ36nmの配線は非常に難しい。最低でもLELELE(露光→エッチングを3回繰り返す)になるが、今度はちょっとしたマスクのずれが致命的な結果になりがちで、実際量産過程で適用するのはかなり困難である。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第870回
PC
スマホCPUの王者が挑む「脱・裏方」宣言。Arm初の自社販売チップAGI CPUは世界をどう変えるか? -
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 - この連載の一覧へ














の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")



























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")

















