




ハイパースケーリングを放棄し
配線ピッチを広げるしかない
ではどうするか? といえば、ハイパースケーリングを放棄すればいい。TSMCはすでに量産を開始している7nm世代のMetal Pitchの詳細を明らかにしていないが、実は(今は無き)Globalfoundriesの7nm世代とかなり近いパラメーターになっているらしい。そのGlobalfoundriesの7nm世代の場合、以下のようにインテルに比べるとはるかにコンサバティブな構成で、M0~M3まではSADPによる構成である。
| Globalfoundries7nm世代の配線間隔と素材 | ||||||
|---|---|---|---|---|---|---|
| 配線層 | 配線間隔 | 配線素材 | ||||
| M0 | 40nm | 銅+コバルトライナー | ||||
| M1 | 56nm | 銅+コバルトライナー | ||||
| M2/M3 | 40nm | 銅+コバルトライナー | ||||
| M4~M9 | 80nm | 銅 | ||||
| M10/M11 | 128nm | 銅 | ||||
| M12/M13 | 720nm | 銅 | ||||
要するにインテルもこれに近いところまで配線ピッチを広げてやれば、VIA Pillerもはるかに容易になる。実際TSMCは7nm世代でVIA Pillerを実現している。
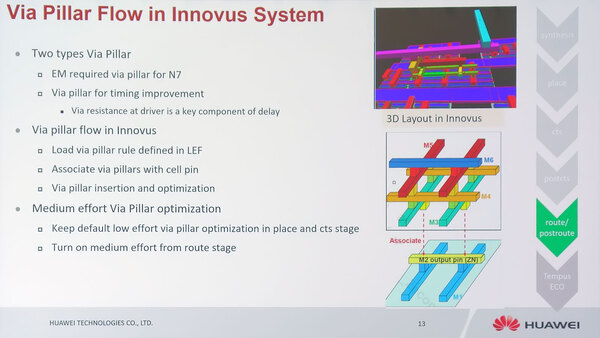
今年のArm TechConにおけるHuaweiとCadenceのセッションより。TSMCの7nmを使ってCortex-A76をインプリメントする際のVia Pillarの適用についてのスライド
これに近いところまで配線層のデザインを緩めれば、諸々の問題はかなり解決する。ついでにContact Over Active Gateもやめてしまえばさらに楽になる気がするが、さすがにこれをやるとトランジスタ層も作り直しになるだけに、そこまで踏み切ったかどうかは定かではない。
Intel Foundryビジネスは失敗
10nmへの投資を回収するのが先決
さて冒頭のSemiAccurateの記事に戻る。これを書いたCharlie Demerjian氏(余談だが、海外取材に行くとほぼ必ず顔を合わせる知り合いである)はきちんと裏を取るのが常なので、この記事が間違ってるとも思えない。
しかし、インテルの反論も、なにしろ公式アカウントでのメンションなので、嘘をついていると後で証券取引等監視委員会からこっぴどく叱られる羽目になる。つまり両方正しい、と筆者は考えている。
要するに昨年までインテルがアナウンスしていた、ハイパースケーリングに基づく10nmプロセスはおそらくすでになくなっている。代わりインテルはコンサバティブな配線層を持つ、新しい10nmプロセスを開発中で、これは順調に推移しているということだ。
しかし配線層そのものの作り直しになるため、これに基づくチップのデザインも相当後送りになるのは免れない。おそらく現時点ではまだ10nmプロセスの配線層そのものの再設計の最中で、年末までにこれを突貫で終わらせ、すぐさまIce Lakeの再設計に入り、来年第2四半期末か第3四半期はじめあたりにこれが完了。すぐさま量産に入り、年末までにチップが出てくるかどうか、という感じのタイムラインなのではないかと思われる。
なぜまだ配線層の再設計が終わっていないと判断するかというと、公式にハイパースケーリングを放棄する路線が確定したのは、今年6月21日以降だろうと考えているからだ。ハイパースケーリング路線を強力に推進していたのが前CEOのBrian Krzanich氏だったことを考えると、彼が居なくなったことでプロセス開発の方向性が変わっても不思議ではない。
ただこの方向性の変更は、すなわちIntel Foundryのビジネスの失敗を意味することでもある。なにしろハイパースケーリングが同社の最大の売りだったわけで、その売りがなくなったらTSMCやSamsungに対するアドバンテージはなくなってしまう。
現実問題として、Intel Foundryは現時点でビジネスとして成立していない。14nmは自社生産で手いっぱい。10nmはまだ量産開始に至っておらず、売り物になるのは22ULPのみという状況では、とりあえず10nmの量産を始めて一刻でも早く10nmへの投資を回収するのがまず大前提で、これがちゃんと動いてから改めてFoundryのビジネスを考え直そう、という健全な判断に至ったのではないか、と筆者は考えている。
実際こう考えると、インテルが10nmプロセスに箝口令を敷いていることや、今年に入ってからTechnology&Manufactureing Dayを開催していないといったことにも符丁が合う。
というより、今回の記事は筆者の願望でもある。この路線をとれば、とにかく来年末からは10nm製品がちゃんと出てくることに期待が持てるわけで、そうなれば持ち直すのは難しくないと思われるからだ。
今のままでは、Novellとか3COMのような結末になりそうで、正直怖いというのが偽らざる感想である。
2017年~2018年のインテルCPUロードマップ
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 -
第873回
PC
「銅配線はまだ重要か? 答えはYesだ」 NVIDIA CEOジェンスンが語った2028年ロードマップとNVLink 8の衝撃 -
第872回
PC
NVIDIAのRubin UltraとKyber Rackの深層 プロトタイプから露見した設計刷新とNVLinkの物理的限界 - この連載の一覧へ









































ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












