




グーグルは2018年7月6日、独自開発の深層学習用カスタムチップ「Tensor Processing Unit(TPU)」に関するメディアセミナーを開催。Google Cloud デベロッパーアドボケイトの佐藤一憲氏が、5月の「Google I/O 2018」で発表した「TPU 3.0」、TPUのリソースをGoogle Cloud Platform(GCP)のクラウドサービスとして利用する「Cloud TPU」、複数ユニットのTPUを接続して大規模な深層学習の計算処理を行う「TPU Pod」について解説した。
GoogleデータセンターのCPU/GPUリソースが足りなくなった
TPUは、ニューラルネットワークの計算に特化した設計を持つASIC(カスタムチップ)。Googleが独自開発し、同社のデータセンター内に実装している。
TPUの開発背景について、佐藤氏は、「従来、Googleデータセンターでのニューラルネットワークの計算にはCPUやGPUを利用していた。しかしながら、2013年頃からニューラルネットワークを活用するシステムが増え、このままではGoogleの全データセンターの2倍の計算リソースが必要になるという予測があった。そこで、より効率がよく、計算リソースのコストを抑えてニューラルネットワークの推論と学習ができる専用チップを開発した」と説明した。
ニューラルネットワークの計算処理には、データから深層学習モデルを構築するためにデータの大規模処理が必要となる「学習」フェーズと、構築した深層学習モデルから結果を出力する「推論」フェーズがある。
Googleが2016年5月に発表した第1世代の「TPU v1」は、深層学習フレームワーク「TensorFlow」で構築したモデルの「推論」のみを扱う設計だった。翌2017年には「推論」と「学習」の両方に対応する第2世代「TPU v2」を発表。2018年5月には水冷式を採用した「推論」と「学習」用の第三世代「TPU 3.0」を発表している。

第1世代の「TPU v1」と「推論」と「学習」の両方に対応した第2世代の「TPU v2」

水冷式を採用した「推論」と「学習」用の第三世代「TPU 3.0」
ニューラルネットワーク計算には32ビットもいらない
TPUは、ニューラルネットワークの計算においてCPUやGPUよりも性能が高い。例えばTPU v1では、Intel Haswell CPUと比較して、ニューラルネットワークの計算性能は15~30倍、電力性能は30~80倍だとする(TPU v1の消費電力は40W)。CPUやGPUよりも性能が高い理由は、「計算精度の最適化」と「行列演算に特化した設計」にある。
ニューラルネットワークの計算は、大まかに、入力データ1に「重み」と呼ばれる数値を掛け合わせた結果の出力データ1に対して、次は出力データ1を入力データ2として計算することを何層も繰り返しながら、各層の「重み」を調整する行列演算になる。「この行列演算では正確な計算結果を得る必要はなく“重み”を見ればよく、演算器のビット数を32ビットから落としても精度は保たれる」(佐藤氏)。TPUでは、8ビット演算器で推論、16ビット演算器で計算を行う設計になっている。
また、CPUとGPUでは演算ごとにメモリ(レジスタ)への読み書きが発生するのに対して、TPUは、行列演算の最初と最後だけメモリへアクセスする設計になっている。「行列演算の途中はメモリへアクセスせず、計算結果を次の層の計算にバケツリレー的に渡せる」(佐藤氏)。
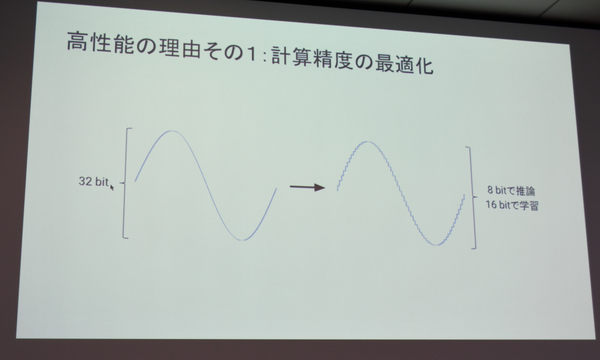
TPUは8ビットで推論、16ビットで学習

TPUでは行列演算の最初と最後しかメモリにアクセスしない
「計算精度の最適化」と「行列演算に特化した設計」により、TPUはメモリの読み書きで消費する電力を抑え、小さい面積にたくさんの演算器を集約できる。TPU v1では1ユニットに6万5536個の8ビット演算器、TPU v2では3万2768個の16ビット演算器を集約している。例えばディープラーニングやシミュレーション計算用途のGPU「Tesla K80」では32ビット演算器が2496個あるのと比較すると、集約度が格段に高いことがわかる。
複数ユニットのTPUで大規模演算ができる「TPU Pod」を年内提供
Googleは、同社データセンター内に配備したTPUをGoogle Search、Google Translate、Google Photosなどのサービスプラットフォームとして自社利用しているほか、GCPのクラウドサービス「Cloud TPU」として外部向けに提供している。2017年5月に申し込みベースで提供を開始し、2018年2月にはベータ版として誰でもTPUリソースが利用できるようになった。
現在提供中のCloud TPUは、64GBメモリを搭載し、1つのTPU v2ユニットあたり最大180テラFlopsの浮動小数点演算が可能だ。利用料金は1時間あたり6.5ドル。TensorFlowからTPUコードへ自動変換するツールや、Cloud TPUですぐに動く画像認識や音声認識、機械翻訳などのモデルも提供している。
さらにGoogleは、より大規模な深層学習計算のために、複数のTPUユニットを自社データセンターネットワークに接続したコンピュータ「TPU Pod」を構築している。TPU Podの性能は1ポット(16ユニット)あたりTPU v2で最大11.5ペタFlops、TPU 3.0のTPU Podでは最大100ペタFlopsを超えるという。年内には、TPU v2のTPU PodがGCPの製品として提供される予定だ。

TPU v2のTPU Pod

TPU 3.0のTPU Podの一部
本記事はアフィリエイトプログラムによる収益を得ている場合があります



