




予想通り、GTC 2016でNVIDIAのGP100コアが発表された。今回はこのGP100の内部アーキテクチャーを主に解説しよう。
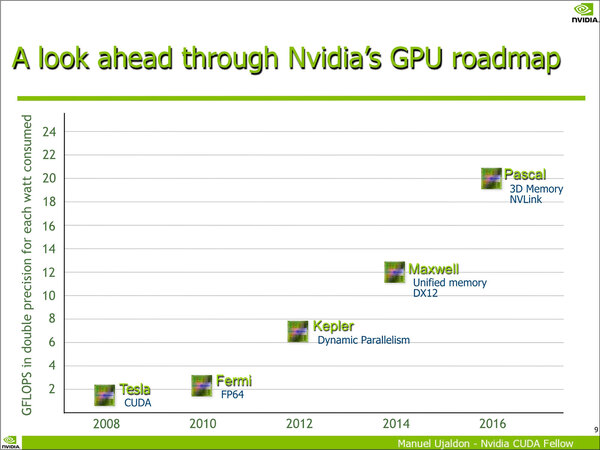
2014年~2017年のNVIDIA GPUロードマップ
Pascal世代の想定性能は
単精度で12TFLOPS、倍精度で4TFLOPSあたり
まず製品全般としてのロードマップであるが、前回のロードマップアップデートからほとんど変わらない。唯一違いがあるのは、どうも製品名は4桁にはならない、つまりGeForce GTX 1080にはならないらしい、ということだけである。
では、例えばGeForce GTX R80などになるのかS80になるのか、はたまたZ80なのか、といった具体的な話はまだ伝わって来ていない。とりあえず数字4桁の製品名はあまり好ましくはないと考えているのだそうで、数字は3桁に減らさせることになると思われる。
ちなみにGeForceグレード製品のスペックそのものは相変わらず不明のままで、HBM2/GDDR5X/GDDR5の使い分けかたも、まだ明らかになっていない。このあたりは、もう少し後で論じたいと思う。
さて、話をGP100に戻そう。昨年6月の話になるのだが、バルセロナ スーパーコンピューティング センターでPACT Cource:Introduction to CUDA Programmingというトレーニングコースが開催された(今年も5月末~6月に開催される)。
ここで“Innovations and futures of GP memory”というセッションが、NVIDIAのFellowであるManual Ujaldon氏を講師として開催されたのだが、このセッション資料がなかなか興味深いものだった。
このセッションは、2016年のPascalで3D積層メモリーを採用するという話を前提に、具体的にどんな形で利用可能になるかを論じたものである。
Pascalでは3D積層メモリーを採用する。この情報そのものは既知

2015年の段階の試作品。今回のGTCで展示されたものと比べると、穴の位置や電源回路などに微妙な違いが見られる
このセッションがおもしろいのは、この時には3D積層メモリーとしてHBMではなくHMCを主に取り上げていたこと、それとPascal世代の性能(単精度で12TFLOPS、倍精度で4TFLOPS)を示していたことだ。
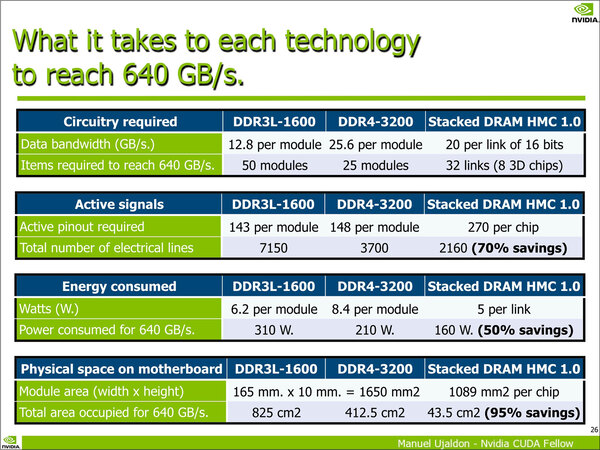
DDR3L-1600とDDR4-3200、それとHMC 1.0を比較するというおもしろい議論。主記憶としてのHMCという位置付けでのメリット/デメリットの議論である
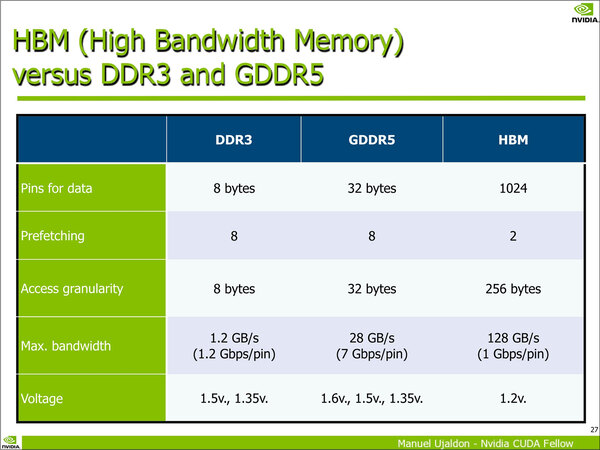
こちらはオンボードメモリー(つまりVRAM)としての特徴を比較したもの
ただスライド全部を見ても、PascalはHMCを使うとはどこにも書いてなく、単にHMC(ないしこれ相当の3D積層メモリー)を使うと、こんな具合に性能が上がるよ、ということでしかない。
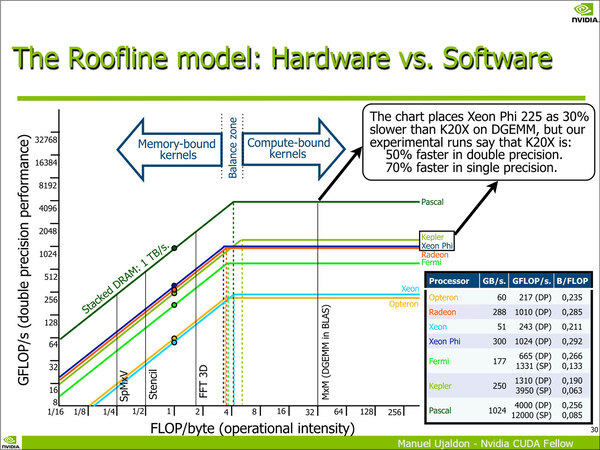
主眼は、3D積層メモリーを利用した場合、演算性能/メモリー帯域がどういう関係になるかを示したもの。KeplerやXeon Phiと比べて、Pascal+3D積層メモリーは高いバランスを取っていることが示されている
そもそもこのセッションは、大学など研究機関の研究者に向けて、CUDAを使うことで高い演算性能を利用できるので使ってほしいという無償のものであり、多分にマーケティング要素が含まれているとは言っても、あからさまな嘘はつけない。
したがって、少なくとも昨年6月の時点におけるPascal世代の想定性能は、単精度で12TFLOPS、倍精度で4TFLOPSあたりを目指していたと思われる。メモリー帯域はHMC 1.0×4と同等の帯域を予定していたというあたりだろう。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第870回
PC
スマホCPUの王者が挑む「脱・裏方」宣言。Arm初の自社販売チップAGI CPUは世界をどう変えるか? -
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 - この連載の一覧へ















の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")



























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")

















