




今回からスーパーコンピューターの系譜は、少しだけ横道に逸れる。何の話かと言えばコプロセッサー/アクセラレーターである。
アクセラレーター、という概念はHPCに限らず昔から広く利用されてきていた。例えばIntel 8086にはIntel 8087なるコプロセッサーが利用できるようになっていたし、似たようなものとしてはMotorolaの68881やNational SemiconductorのNS32081など、もう並べ立てると山のように出てくる。

Intel 8087。画像はWikimedia Commonsより(http://commons.wikimedia.org/wiki/File:Intel_8087.jpg
この連載でもコプロセッサーの歴史を連載212回でまとめている。要するに浮動小数点演算を行なわせるためのものだ。なぜこれがコプロセッサーの形になったかというと、回路規模の問題である。浮動小数点演算をある程度の有効桁数で実行させようとすると、そこで必要とされる回路はかなり大きくなる。
昔の半導体製造技術では、この回路規模がメインとなるプロセッサーより大きかった。例えば8086はトランジスタが2万9000個で構成されるが、8087は4万5000個だった。
これを1つにしてしまうと、CPUを構成するダイのサイズが倍以上に膨らんでしまいかねない。これは歩留まりに深刻な影響を与えるサイズで、製造上の理由により分割したかったというのが1つ。
もう1つは、CPUの原価は結局ダイサイズで決まるので、FPUを統合すると原価が倍以上になる。ところが当時、そうした浮動小数点演算を高速に行ないたいというユーザーはそれほど多くなく、大多数のユーザーはFPUを統合して価格が上がることを好まなかった。
とはいえ、HPCの市場では浮動小数点演算が遅いとまるで意味がない。したがって、汎用プロセッサーを使うマシンの場合は必ずFPUをペアで使うことが普通だった。インテルのiPSC/1やiPSC/2などは、この典型例であろう。

iPSC/1。画像はComputer History Museumより
また、FPUを持たないプロセッサーの場合、外付けの形でFPUを追加した。たとえばThinking MachinesのCM-2はWeitek WTL3132 FPUをシステム全体で2048個も搭載しているが、これなど典型的な例であろう。

CM-2。画像はComputer History Museumより
これがコプロセッサーとアクセラレーターの違いでもある。上記の例で言えば、iPSC/1やiPSC2はコプロセッサーで、CM-2はアクセラレーターとなる。では両者はなにが違うかというと、プロセッサー側が当初からそれを使うことを想定したものがコプロセッサー、外部に汎用の形で接続されるのがアクセラレーターというのが一般的な認識である。
8087/80287/80387といったFPUの場合、8086/80286/80386と組み合わせて使うことが前提となっており、ハードウェア的にも専用のI/Fが用意されている。またソフトウェア的にも命令セットの中に当初からFPUを使うための命令が含まれており、これを使うことでFPUを駆動できた。「コプロセッサー」と称する場合は、こうした形で当初から利用することを前提としたものを指すのが普通である。

Intel 80387SX。画像はWikimedia Commonsより(http://commons.wikimedia.org/wiki/File:KL_Intel_i387SX.jpg)
アクセラレーターとは、当初から組み合わせることを想定しない汎用的なものを指す。CM-5の場合がまさしくそうで、搭載されたWeitekのWTL3132は(名前はともかく)使い方は34bitの命令ポートと32bitのデータポートでつなげるだけの構成であり、速度を無視してよければ汎用I/Oポートをそれぞれのポートにつなぐだけで使えた。
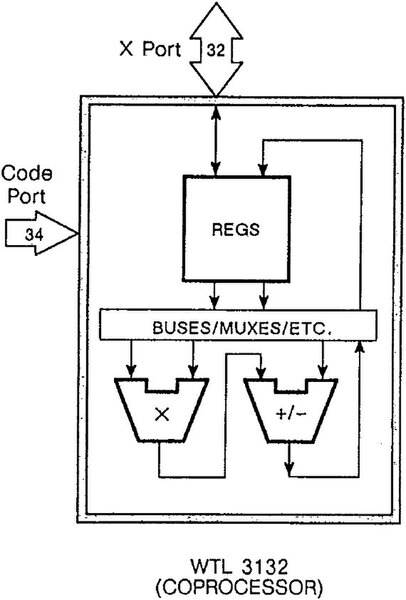
WTL3132の構成。Weitek WTL3132/3332のデータシートより。ここでWTL3132が“COPROCESSOR”とされるのは、同じFPUのエンジンながら入出力ポートが分離されたWTL3332という製品は“DATA PATH”とされ、これとの対比のためと思われる
命令セットにはWTL3132の命令は含まれていないので、汎用I/Oポート経由で以下のようにして使う。
- (1) X Portに演算対象となるデータを格納する
- (2) Code Portに演算命令を格納する
- (3)演算処理が終わった頃を見計らい、X Portより演算結果を取り込む
結構オーバーヘッドは多いのだが、それでもソフトウェア的に浮動小数点演算を行なう場合に比べると何倍も高速ということで愛用された。
ちなみにさらに高速化するには、例えば演算元データの格納や演算結果の取り込みは、ポートI/OではなくDMAを使ったほうが良いし、毎回(1)~(3)を繰り返すのではなく、(1)で8回分の演算元データを格納、(2)を8回繰り返し、最後に(3)でまとめて8回分のデータを取り込むといったやり方がオーバーヘッド削減になる。
ついでに言えば、「終わった頃を見計らう」のではなく、演算が終わったら割り込みでも飛ばしてくれるほうがよりスマートだろう。もちろんWTL3132にはDMAや割り込みの機能はないが、複数回の演算をまとめて実行くらいはアプリケーション側でなんとかなるので、その程度のチューニングは行なわれたであろう。
(→次ページヘ続く 「プロセッサーの高性能化で廃れたアクセラレーター」)
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ




























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






























