




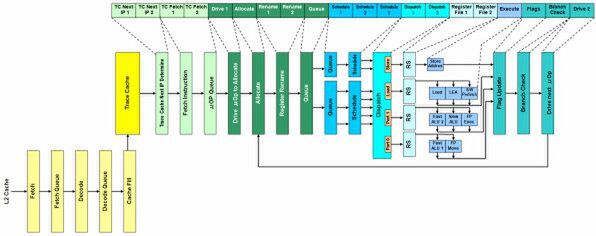
図1 Netburst Architectureのパイプライン構造図
次がようやく「Execute」、つまり命令を処理するステージとなる。ここは1サイクルで処理できるのだが、それにはわけがある。通常なら命令を処理すると、それにともなって結果をステータスレジスタに設定する必要がある。Netburst ArchitectureではこれをExecuteからはずして、次に「Flag Update」というステージを用意している。
また、分岐命令やジャンプ命令でなければ、「次の命令」は現在処理した命令の次になるが、分岐やジャンプが来ると「次の命令」の位置は変わる。この処理も通常はExecuteに含まれるのだが、Netburst Architectureでは「Branch Check」という別ステージを用意している。その結果として、「次」のμOpの位置を確定する作業を、最後の「Drive next μOp」というステージで行なっている。これらはいずれも1サイクルで処理できるのだが、トータルすると4サイクルを要していると考えるほうが実情に近いだろう。
Trace Cache前にも存在する
Netburst Architectureのステージとは
「20段のパイプライン」は以上のとおりなのだが、冒頭で述べたように実際のNetburst Architectureには、もう少しステージがある。最初のスライドを見直してみよう。

Pentium IIIとPentium 4のパイプラインの比較
これはPentium IIIとPentium 4での「Misprediction Pipeline」、つまり分岐予測が外れた場合の比較である。分岐予測が外れた場合、Pentium IIIでは素直に1次命令キャッシュからフェッチしなおすが、Pentium 4ではTrace Cacheからフェッチできる。ただし、これは間違ってはいないのだが、完璧に正しいとも言えない。
WillametteではTrace Cacheが1次命令キャッシュ扱いされているが、Trace Cacheはあくまで「μOpを保持するキャッシュ」である。そのためこれまでに示した20段とは別に、x86命令をフェッチ/デコードして、その結果のμOpをTrace Cacheに格納するステージが別途必要である。それが図1で左下に示した部分である。
インテルはこれらのステージについて、いまだ詳細を明らかにしていないが、「Intel Technology Journal Volume 06 Issue 01」では、次のような図が示されている。
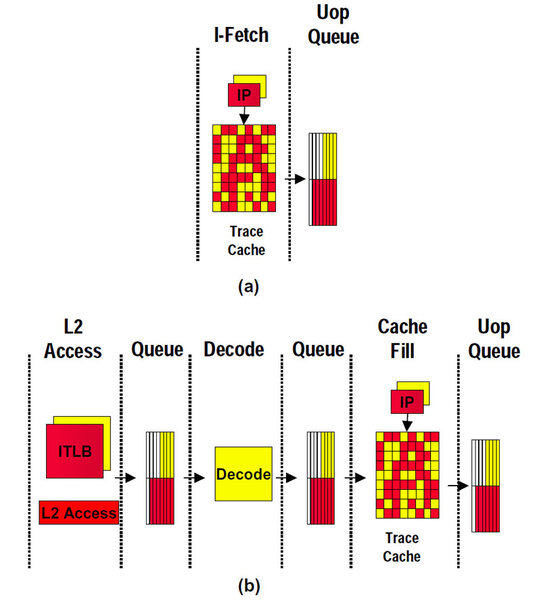
Trace Cacheヒット時(a)とミス時(b)の動作の違い。Trace Cacheがヒットしている間は、その前のステージは動かない(a)。Trace Cacheがミスすると、2次キャッシュから命令を取り込んでデコードし、Trace Cacheに埋める作業が必要になる(b)
図の(a)は、分岐予測が外れたがTrace Cacheにはヒットしている場合。(b)は分岐予測が外れたうえ、Trace Cacheもミスした場合である。(b)の場合にどの位のサイクルが余分にかかるかは明確でない。
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ










が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")

















