




4つのスケジューラーで命令を分別処理
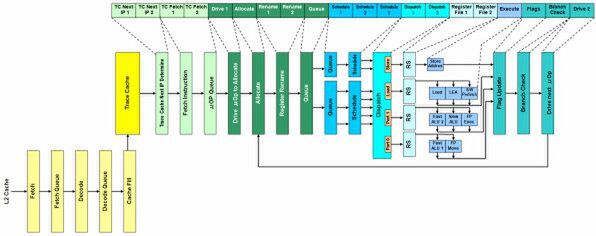
図1 Netburst Architectureのパイプライン構造図
次の「Drive 1」というステージは、μOp Queueから命令を取りこんで次の「Drive μOp to Allocate」に渡す作業を行なう。Drive 1は最大で、3μOpを同時にハンドリングできる。
ここで取り込んだ命令を「Re-Order Buffer」(ROB)に登録したり、Register Fileへの割り当てや、Load/Store命令のキューへの登録をするのが、次の「Allocate」ステージである。Willametteの場合、ROBは126エントリ、Register Fileは128エントリが用意される。またLoad/Store命令は、それぞれ48/24エントリのキューが用意されている。
これに続く2ステージは「Register Renaming」で、命令中のレジスタ指定を、Allocateで割り当てたRegister Fileに置き換えたりする処理をする。次の「Queue」ステージは、Renamingが終わった命令をLoad/Storeとその他に分離して、それぞれ異なるスケジューラーに割り当てて送り出す。
「Schedule 1~3」は3サイクルを要する。パイプライン構造図ではスケジューラーを上下2つに分けているが、厳密に言えば以下の4つに分かれている。下のスライドを見るとわかりやすい。
- Integer Fast Scheduler
- Simple FP Scheduler
- Slow ALU/General FP Scheduler
- Memory Scheduler
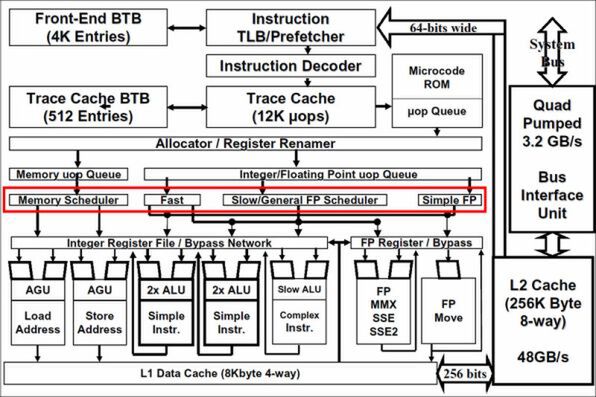
インテルの示すNetBurst Architectureの内部構成図。赤枠部分が4つのスケジューラーで、Allocate/Register Renamerからスケジューラーを通って実行ユニットまでの複雑な接続がわかる
「Integer Fast ALU Scheduler」というのは、端的に言えばx86命令がそのままひとつのμOpで表現される類の、処理が簡単な命令用スケジューラーだ。同様に、「Simple FP Scheduler」も処理が簡単な浮動小数点演算のスケジューラーである。「Memory Scheduler」はLoad/Store命令専用。「Slow ALU/General FP Scheduler」は、それ以外の命令全部を担当するスケジューラーである。まずQueueの出力をいったん個別のQueueで受け、それを個々のALUに向けて割り当てるのが、このSchedule 1~3の処理となる。
Scheduleにより、実行ユニットにあわせて別々の経路で命令が整理されて送り出される。これを実際に各実行ユニットに発行するのが「Dispatch」で、これに2サイクルを要する。なお、上のスライドを見ると、同時7命令が発行できそうに思えるが、実際にはWillametteの命令発行ポートは4つしかなく、どう頑張っても同時4命令しか発行できない仕組みだ。
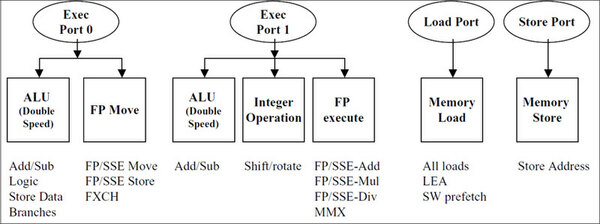
Dispatcher(命令発行ポート)と実行ユニットの関係。命令発行ポートは4つで、この下にさまざまな実行ユニットがぶら下がっている
DispatchとExecuteの間にある「Register File」というステージは、演算に必要な値をRegister Fileから読み出す処理である。これにも2サイクルを要する。
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ








が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")



















