




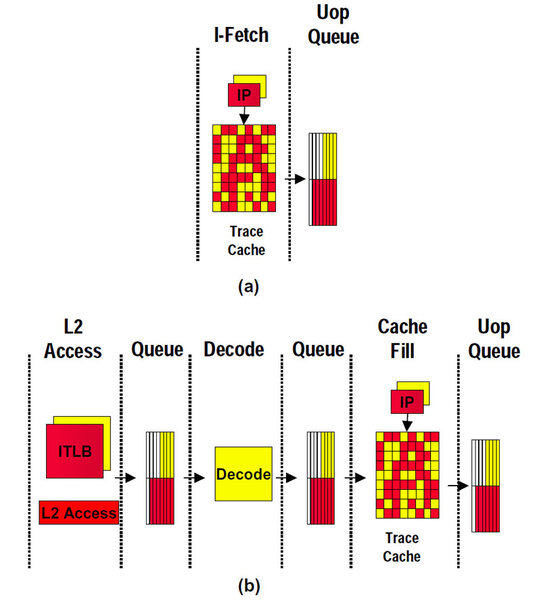
Trace Cacheヒット時(a)とミス時(b)の動作の違い。Trace Cacheがヒットしている間は、その前のステージは動かない(a)。Trace Cacheがミスすると、2次キャッシュから命令を取り込んでデコードし、Trace Cacheに埋める作業が必要になる(b)
ところで、(a)と(b)に赤と黄色があるのは、この図が元々ハイパースレッディングの説明に使われているからである。図が示すのはTrace Cache以前の部分であるが、Trace Cache以後はどうなっているかというと次の図のようになる。
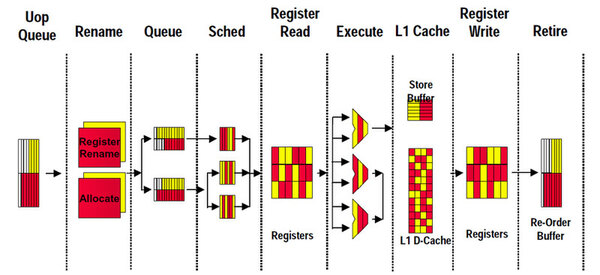
ハイパースレッディングの動作を説明するための図。部分的に簡略化されているので、筆者の図1とは微妙に異なる
この図の見方だが、例えば「Register Rename」や「Allocate」は、ハイパースレッディング有効時には物理的に2つに分けるように実装されている。一方で「μOp Queue」や「Retire」の部分にあるRe-Order Buffer、Store Bufferなどは、物理的にはひとつだが内部では論理的にスレッド別となる。スケジューラーやExecute、1次データキャッシュなどは、スレッドにかかわらずごちゃ混ぜとされる。
つまり、ハイパースレッディングを実装するにあたって物理的に増やさなければいけないのは、「IP」(命令ポインタ)と「I-TLB」(命令TLB)、Register RenameやAllocateのテーブルのみ程度(Register Fileそのものは共用)。これによるダイサイズの増加は、数パーセントで済むという。
もともとハイパースレッディングそのものが、早い時期からNetburst Architectureと対になる形で実装を予定していた技術であり、パイプライン構造そのものがハイパースレッディングを容易に実装できるように考慮されていた。Netburst Architecureの持つ「実行ユニットの利用効率が低い」問題の解決案として、ハイパースレッディングが採用されたようなものだから、事実上両者は一体のものと考えてもいいだろう。
★
Pentium 4のもうひとつのトピックは、「倍速ALU」である。要するに、単純命令を処理するALUは、コアの動作速度の2倍速で動作するというものだ。ただしこの倍速ALUは、一度にデータ処理できる幅は16bit分しかない。そのため32bit命令を処理すると、等速のALUと同じ処理性能にしかならない。
インテルはこれを採用した理由として、「より遅延が少なく処理できること」と「ダイサイズの節約になること」の2点を挙げたが、付け加えれば依存関係の解消にも若干効果的ではある。ただしその代償は「消費電力の急増」で、これは90nmプロセスの世代で顕著になった。
次回はWillametteの発展型である「Prescott」の内部について解説しよう。
この連載の記事
-
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 -
第757回
PC
「RISC-VはArmに劣る」と主張し猛烈な批判にあうArm RISC-Vプロセッサー遍歴 - この連載の一覧へ






が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")





























