





「NetBurst Architecture」を代表する、Northwoodコアの「Pentium 4」
一連のインテルのメインストリーム製品に関しては、前回の「Haswell」までで解説が終わった。CPUパイプラインの進化を辿るシリーズの締めくくりとして、2つほど「その他」のインテルCPUについて解説したい。ひとつめは、「Pentium 4」」シリーズで投入された「NetBurst Architecture」である。
「20段のパイプライン」と称する
Netburst Architectureの中身
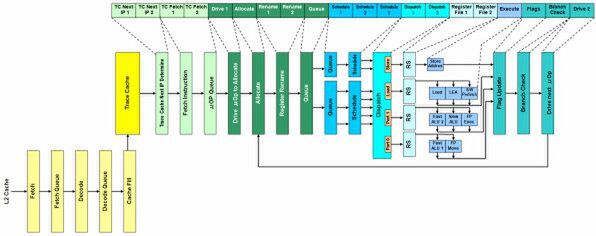
図1 Netburst Architectureのパイプライン構造図
2000年当時、180nmプロセス「Coppermine-T」コアの「Pentium III」が1.13GHz止まりだったのに対して、同年発表された「Willamette」こと初代Pentium 4は、180nmプロセスで2GHz駆動を実現した。同一周波数での性能はPentium IIIに及ばないものの、より高い動作周波数をサポートすることで、トータル性能でPentium IIIを圧倒することで性能改善をはたした(関連記事)。続く130nmプロセスの「Northwood」では、動作周波数は最大3.4GHzに達し、順調に性能を上げることに成功した。
ちなみに、Pentium ProことP6のアーキテクトの1人であるロバート P.コルウェル(Robert P.Colwell)氏の著書「The Pentium Chronicles」によれば、Willametteの開発は1994年あたりに始まったようで、開発開始から製品化まで6年近くかかったことになる。もっとも、Pentium Proも開発開始は1990年、製品出荷が1995年末であった。まったく新規にアーキテクチャーを開発する場合、俗に言われる「4年程度」では、まったく足りないということかもしれない。
そのNetburst Architectureだが、よく知られているようにパイプライン段数は20段にも及ぶ。ただし、この20段というのはあまり正確ではなく、トータルではもう少し多い。よく20段と称される数字の根拠が下のスライドだが、実はこれがパイプラインのすべてではないからだ。

「Intel Technology Journal Q1, 2001」に記載されていた、Pentium IIIとPentium 4のパイプラインの比較。Pentium 4が20段となっている
だがまずは20段の解説から始めよう。Netburst Architectureの特徴は「Hyper Pipeline」と呼ばれるもので、従来ならば1ステージで済ませる分を、複数ステージに分割するというものだ。これにより、1ステージの処理に必要な時間が短縮でき、結果として高速動作が可能になる。そのため、実質的なステージ数は12段ほどとなる。
最初の「TC Next IP」は、Trace Cacheから次の「命令の位置」を確定するステージだ。これに2サイクルを要している。ここで確定した次の命令を、Trace Cacheから取得するのが、それに続く「TC Fetch」である。TC Fetchで取得した命令は、いったん「μOp Queue」に格納される。実を言えば、このTC Next IP1から「TC Fetch 2」までの4ステージが、唯一インオーダー実行される部分である。ここから先はアウトオブオーダー実行になる。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ








































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






















