




ちなみにモバイル向けに関しては、Trinityを使うことで厚さ18mmのノートを構成できる、としている。消費電力が17W以下に抑えられれば、このグレードの製品ができるという訳で、ますます薄型化の競争が激しくなることが予想される。

AMDはTrinityを使えば厚さ18mmのノートを作れると主張する。インテルのUltrabookの要件が20~21mm未満であるそうだから、これにも適う形だ
とは言え、インテルのSandy Bridgeや次に登場するIvy Bridgeと比較すると、現行のLlanoはもちろんTrinityでも性能面ではなかなか苦しいのが否めない。逆にローエンドに関しては、比較的いい勝負になると見ているようだ。まず2012年にHondoを投入するが、インテルの競合製品は32nmで製造されたAtomベースの「Medfield」になるため、CPUコアの性能とGPUの性能の両面で十分競争力があるとAMDは考えているようだ。

Brazos 2.0と従来製品の消費電力比較。Hondoは基本的にはBrazos 2.0の低消費電力版
一方Brazos 2.0であるが、さすがにインテルが2013年に投入する「Haswell」世代と比較すると、性能面でやや厳しいものがあるため、これにあわせてTemashに更新される。このTemash、1ページ2枚目のスライドを見ると「1st gen SoC with integrated FCH」(FCHまで統合した第1世代のSoC)の文言が躍っており、AMDとしては久しぶりに、1チップでシステムが構成できるチップをリリースすることになると思われる。
GPUプログラミングの難しさを解消する「HSA」
ロードマップについてはこのあたりにして、ここからはAMDがKaveri世代から導入する「HSA」(Heterogeneous System Architecture)について解説したい。以下のスライドは、以前にもAMDが何度か示しているものだ。
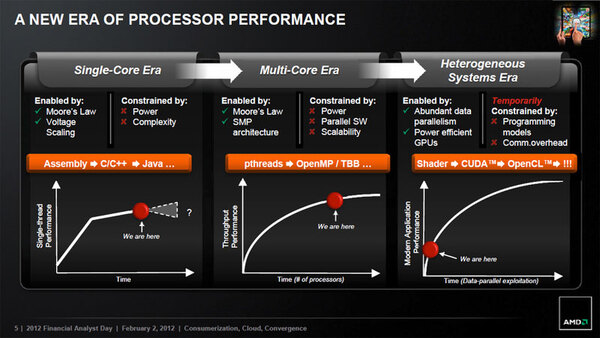
シングルコア世代とマルチコア世代、ヘテロジニアス世代での性能向上手段と、それを制約する要因
CPUのシングルスレッド性能を上げることは、もっぱらプロセス微細化にまつわるもろもろの理由により難しくなっている。シングルコアの場合、プロセスを微細化してもリーク電流が増える一方で、消費電力の観点から動作周波数は上げられない。IPCを増やすのもそろそろ限界だ。そのためCPUはマルチコア化に進んだ。この手法は途中まで効果的だったが、ソフトウェア並列性の限界が見えてきており、コアの数を増やしても効率が落ちるだけで、性能が上がりにくくなっている。サーバー分野はともかくデスクトップやモバイルでは、「もはやコアをこれ以上増やしても性能が上がらない」というところまで来てしまった。そこで、「ヘテロジニアス構成に乗り出そう」というのが、昨今の動向である。
ただそのヘテロジニアス構成にしても、さまざまな問題点が指摘されている。まずプログラミングが難しく、既存のプログラミング環境やOS環境が、そもそもヘテロジニアス構成に対応していない。また通信のオーバーヘッドが、大きなボトルネックになっている。ここで言う「通信」とは、CPUコアとGPUコアの同期やデータの受け渡しのことだ。GPUコアは“汎用”といいつつも、CPUにできることは何でも可能というわけではない。プログラミング的に見れば、「やたら高速なSIMDエンジンがたくさんある」という存在であり、CPU側で「GPUに何をさせるか」を細かくコントロールしてやる必要がある。
厄介なのは、SSEやAVXといった既存のSIMDエンジンの場合なら、CPUコアの中にあるので「命令を発行した」「命令の実行が終了した」「実行の結果としてのデータを書き戻した」といったタイミングは簡単にわかるし、プログラミングの側でもあまり意識せずに使える。ところが今のGPUは、あくまでCPUの外のデバイスである。そのためPCI Express経由で明示的に、GPUコアに対してデータを送り込んでから処理を行なわせ、処理が済んだら割り込みルーチンなどでその通知をCPUが受け取り、この割り込みルーチンの中で計算結果をGPUからCPUのメモリーに転送する、といった手間のかかる処理が必要になる。
実はこれが理由で、GPUを使う場合はある程度規模の大きなデータを処理するのでないと、さっぱり効率が上がらない問題がある。ところが規模の大きなデータは、送り出すのにも受け取るのにも時間がかかるという別の問題があり、これがまたプログラミングの難易度を引き上げている。
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ










が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")

















