





AMDが計画するヘテロジニアス環境の改革ロードマップ。実際は2012~2020年の中でも、どんな形で実装してゆくかに関しては、まだいろいろな話がある
こうした問題に対して、AMDは段階を踏んで対応を進めることを明らかにしている。2002~2008年は完全にCPUとGPUは別物であって、AMDならば「Brook+」や「ATI Stream」、NVIDIAならば「CUDA」といった開発環境によって、明示的にGPUを使うしかなかった。前ページに書いた「GPUを使うための諸々の問題点」というのは、この2008年までの時期の話である。
それが2009~2011年にかけて、「OpenCL」や「DirectCompute」といった、複数ベンダーのGPUをひとつのプログラミング環境でまとめて扱える仕組みが登場した。OpenCLはGPUのみならず、CPUも同じスキームで扱えるようになっており、ひとつの処理をCPUとGPUで並行して行なうことも可能になっている。また、さまざまなプログラミング言語やライブラリーも登場しており、一部ではランタイムの整理なども行なわれてきた。しかしまだ、「OSでナチュラルにGPUを扱える」という域には遠い。こうしたものを2012年以降で整えてゆく、という話だ。
2013年で登場する「Kaveri」「Kabani」というコアで投入される「HSA Application Support」も、その一環である。2012年までのAPUは、CPUとGPUは基本的に別のものであって、周辺回路のみが多少統合されていた。例えば2011年のLlanoは、とりあえずメモリーコントローラーが統合されて物理的に1チップになった程度だった。Trinityではここから一歩進んで、電源管理も統合される。またLlanoの時点で、キャッシュコヒーレンシは極めて限定的ながら実装されており、またCPUとGPUを直接つなぐ「Direct Path」も内蔵された(詳細は後述)。2013年からは本格的に、これが統合される方向に進むとされる。

HSAの改良プラン。本格的に改良されるのは2013年からなので、2012年のTrinityは、Llanoの実装を若干強化した程度になりそうだ
2013年のアーキテクチャーでは
CPUとGPUのアドレス空間が統合される
2013年では、まずCPUとGPUのアドレス空間が完全に統合される。しかもGPUからCPUの仮想メモリーを、直接アクセスできるようになる。さらにCPUとGPUの間で、完全なキャッシュコヒーレンシが実現されるという。
これは何を意味するのか? まずアドレス空間と仮想メモリーだが、これまでCPUにつながったメモリー(いわゆるシステムメモリー)とGPUのメモリー※1は、お互いにアクセスできない仕組みだった。図1で言えば左側の仕組みで、CPUにつながったシステムメモリーはシステム全体のアドレス空間にマッピングされるが、GPUのメモリーはほんの一部だけがアドレス空間にマッピングされるだけで、ほとんどの領域はGPUからしかアクセスできなかい。
※1 ビデオメモリーやフレームバッファなど。統合型の場合は、GPUが管理しているメモリー。
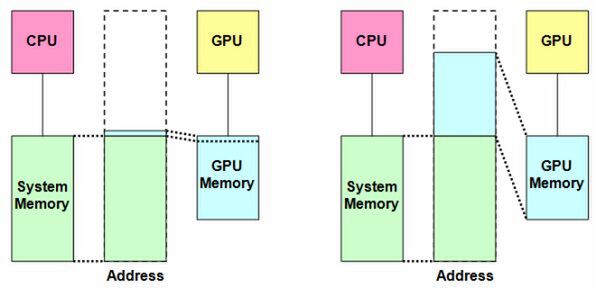
図1 CPUとGPUのアドレス空間統合の説明図。左が現在の環境で、CPUとGPUのメモリーは分断されている。右は統合後で、GPUのメモリーが全体のアドレス空間にマッピングされて、CPUからでもアクセスできるようになる
これが2013年以降は、GPUのメモリーも基本的には全部アドレス空間にマッピングされる(図1右)。それのみならず、GPUはシステムメモリー側にも直接アクセスが可能になる。この世代ではCPUとGPUが同一アドレス空間を共有するから、GPUからアクセスできない理由はない。ただし、GPU側にはシステムメモリーのMMU(Memory Management Unit)はないので、CPU上で動くプログラムがアクセスしている仮想アドレスが、実際はどの物理アドレスになるかまではわからない。そこでCPU側のポインタを使って、システムメモリーにアクセスするという仕組みになっている。
キャッシュコヒーレンシは、キャッシュの一貫性などと呼ばれる。例えば図2のような4コアのシステムがあり、たまたま4つのCPUコアすべてが同じメモリーアドレスのデータ(赤い四角の部分)をキャッシュしていたとする。
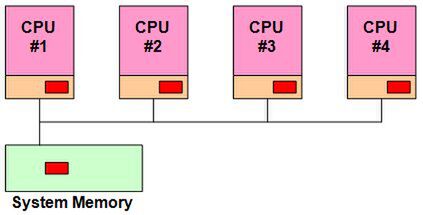
図2 4コアのシステムで、すべてのCPUが同じメモリーアドレスのデータをキャッシュしている状態
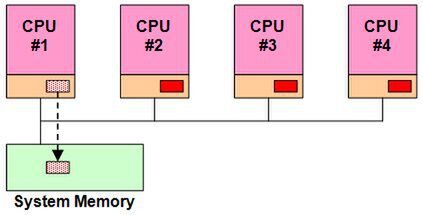
図3 CPU #1がデータを書き換える
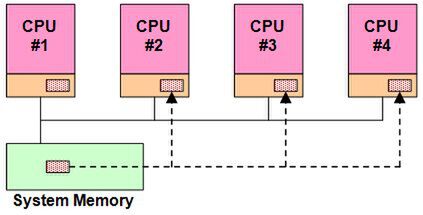
図4 書き換えられたメモリーの内容を、CPU #2~#4のキャッシュに反映させる
この状態で、CPU #1がこのデータを書き換えたとする。CPU #1は直ちにこのデータをシステムメモリーに書き戻す(Write Back)処理を行なう(図3)。このままでは、メモリーの内容とCPU #2~#4のキャッシュの内容が異なったままになるので、メモリーの内容をCPU #2~#4のキャッシュに反映させる(図4)。
この処理を「スヌーピング」などと呼ぶが、こうしたスヌーピングを自動的に行なうことで、すべてのCPUのキャッシュとメモリーが同一の値を取ることを「キャッシュコヒーレンシ」と呼ぶわけだ。2013年にはこれが、CPUだけではなくGPUにも拡張される。
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ








が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")























