




低コスト製品のはずがコストは高く
性能もVoodooの半分以下
低コスト化のためにいろいろと工夫をしたVoodoo Rushであったが、こうした努力が実を結んだとは、正直言いがたかった。まずSST-96そのものの問題があった。先の図1ではSST-96を点線で囲んで、まるで1チップのように示したが、実はSST-96は2チップ構成だった。PUMAインターフェース(PUMA I/F)を内蔵した「FBI」のチップと、「TREX」のチップの2チップ構成という構造は、SST-1ことVoodoo Graphicsから変わっていない。
その上フレームバッファーとテクスチャメモリーに、それぞれ複数個(4~8個)のEDO DRAMチップを搭載する必要があるから、実はこれだけで普通のグラフィックスカードと同じ大きさを占有してしまうことになる。ここに、さらに2Dグラフィックチップを載せようというのだから、その苦労は半端ではない。結局フレームバッファーやテクスチャメモリーの量を抑えて基板上の面積を開けて、そこに無理やり2Dグラフィックを載せる形になった。中には基板を2枚重ねにして、メモリー容量を確保した製品(Hercules Stingray 128/3D)もあった。こうなると、もう当初の「低価格」という目論見が完全に消えてしまった。
しかも3dfx自身、Voodoo Rushは低価格向けと位置づけた関係で、性能が初代Voodoo Graphicsよりも低かった。主要な要因はフレームバッファーを2Dグラフィックと共用したことによる。2Dの場合、画面リフレッシュのために定期的にフレームバッファーへのアクセスが発生する。状況を悪くしていたのは、3D描画の最中でも2D側の画面リフレッシュを止められないことだった。「3D描画時は2Dを止める」といった細工は、当時のグラフィックスカードではできなかった。この結果として、フレームバッファーへのアクセスの最優先権を持つのは2Dグラフィックの画面リフレッシュ要求で、この合間をぬってFBIから3D描画用のリクエストが処理されるという結果になった。
この仕様は、Voodoo Rushの仕様書にも明確に書かれている。下の画像はVoodoo Rushの仕様書に示された3D描画性能の一覧であるが、上側の表がSST-1(Voodoo Graphics)とSST-96(Voodoo Rush)の性能差をまとめたものだ。
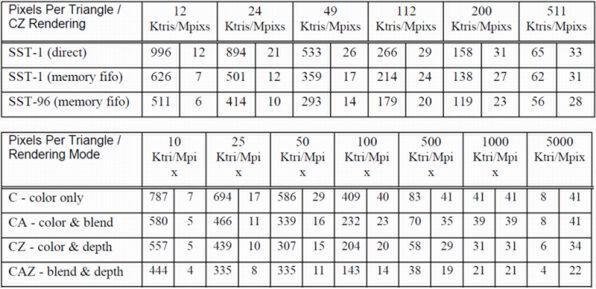
Voodoo Rushの仕様書から抜粋した、VoodooとVoodoo Rushの性能差。SST-1はVoodoo Graphics。トライアングル(三角形)のピクセル数ごとに、毎秒どれだけそのトライアングルを描画できるかをまとめたもの。ちなみにこれは実機でのテストではなく、シミュレーター上での試算
例えばひとつのトライアングルが12ピクセルの場合、Voodoo GraphicsならDirect Modeで99万6000トライアングル/秒(1200万ピクセル/秒)で描画できるのに、Voodoo Rushだと同じ条件で51万1000トライアングル/秒(600万ピクセル/秒)しか描画できない。大きなトライアングル(例えばひとつのトライアングルが511ピクセル)だとそれほど大きな性能差はないが、細かいトライアングルの描画では、ざっくり言ってVoodoo Graphicsの半分程度の性能しか出せていないのがわかるだろう。
加えて言うと、このフレームバッファーやテクスチャメモリーはPCIアドレス空間にマッピングされ、CPUからアクセスできるようになっているのだが、これをアクセスするためには2Dグラフィック側からPUMA経由でアクセスするしかなく、これがまた遅かった。

図1をもう一度掲載。PCとつながる「PCI」が、図左の「2D Graphics」の先にしかない
というのは、先にも書いたとおりPUMA経由でのアクセスには優先順位が設けられていて、以下のような順になっている。
- ①2Dグラフィックからのリフレッシュ用
- ②SST-96のFBIからのアクセス
- ③2Dグラフィックからのアクセス
この場合、PCIバス経由で3D描画に必要なデータ類を書き込む場合でも、PUMAから見ると「2Dグラフィックからのアクセス」としか見えなくなってしまう。2Dからのアクセスでは優先順位が最低になってしまうので、非常に速度が遅くなるという欠点があった。これはPCIインターフェースを2Dグラフィックのみに集約したことによる副作用で、この2つの相乗効果により、Voodoo Rushの3D性能はVoodoo Graphicsの半分「未満」というのが大雑把な性能評価だった。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ











の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")





























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






















