



ロードマップでわかる!当世プロセッサー事情 第882回
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁
2026年06月29日 12時00分更新

SRAMの微細化限界に挑む立体セル構造と
気になる「5年以内の生産」は誰が担うのか
さて今回の発表は2025年のVLSIシンポジウムのものに加え、今年のVLSIシンポジウムの内容も含んでいる。今年はTFS2.5で"Area and Performance of Staggered-Channel NanostackSRAM Bitcells"という講演があった。昨年のものは基本的なNanoStack構造のトランジスタのみの話だが、今年はこれを用いて非常にコンパクトなSRAMセルを構築した、という話である。こちらの動機は、ロジックが微細化してもSRAMの密度が上がらない、という問題である。
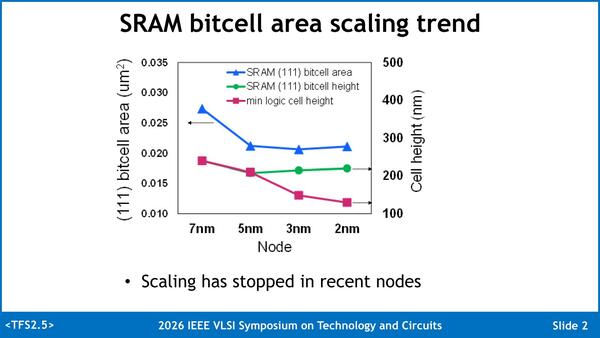
実際には2nm世代になると、3nm世代より密度が落ちたりする。この図でもわかるように、5nm世代が一番密度が高いという有様だ
SRAMとはフリップフロップ回路を2つ組み合わせたもので、通常6T(6トランジスタ)ないし8T(8トランジスタ)構成を使うことが多い(用途や性能に応じて、非常に多数のSRAMの回路がある)。で、ほとんどのものの場合、SRAMを構成する場合に面積を喰うのはトランジスタそのものではなく、トランジスタ同士をつなぐ配線である。
したがって、配線密度が上がるとSRAMの密度も上がりやすいが、トランジスタの密度が上がってもSRAMの容量が変わらない、ということが起こりえる。なぜかといえば、1bit分のSRAMであればそれほど問題ないが、当然それでは意味がないので大量に並べてしかもアドレスバスでアクセスできるようにする必要がある。このアドレスでのアクセスのためにWL(Word Line)とBL(Bit Line)という交差する配線を巡らせる必要があり、この配線がほぼSRAMのセルサイズを決定していた。
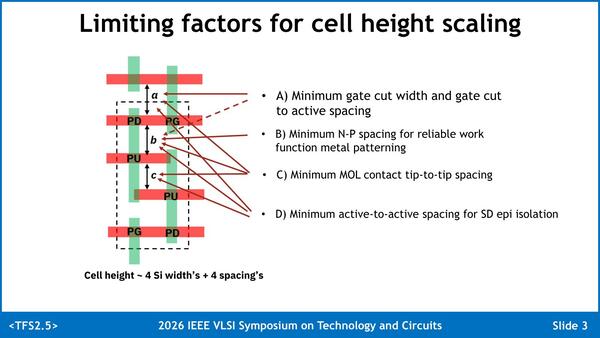
これは従来型のSRAMセルでの構造の模式図。破線で囲われた部分が1bit分のSRAMセルである。a/b/cという間隔を詰めるための物理的な障害が多かったのが、密度を上げられなかった理由である
今回IBMはこれを大幅に小型化するという提案をしたわけだ。
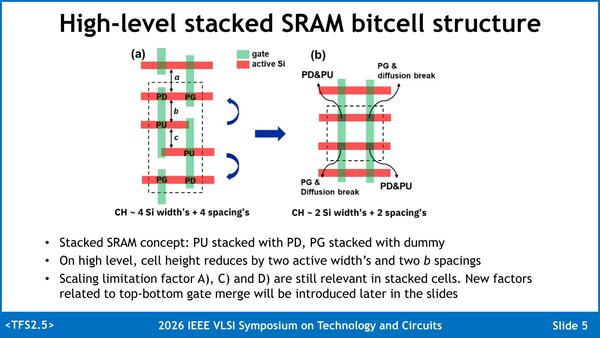
(a)が従来型、(b)が今回のstacked SRAMである
細かい構造の説明は省くが、物理的には下の画像のように立体構造にするとともに、ゲートを共通化することで大幅な小型化が可能になった、というものである。一応シミュレーションでは従来型のSRAMセルと変わらない性能が確保されており、それでいてセル面積を40%以上削減できるというのが論文の要旨である。
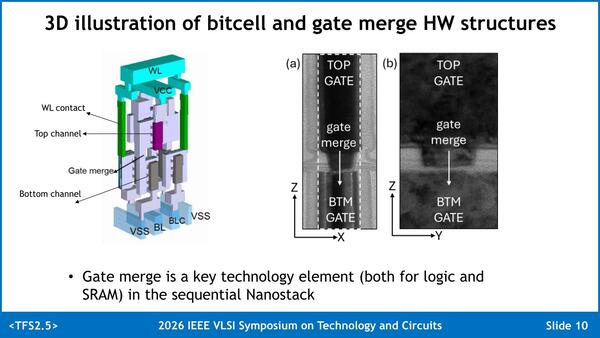
ゲートを共通化させることで、2つ上の画像にあるa/b/cに相当する間隔を大幅に詰められたとしている
実はこのNanoStack SRAM Bitcell、まだ信頼性などに関する話は一切論文に記されていない。あくまでもシミュレーションでの結果のみである。もちろんそれをいきなり量産に回すわけにはいかないので、まずは実際にテストチップを製造して、単に動くだけでなく、細かな特性がどうなっているか、信頼性はどう、といったさまざまな評価をこれから実シリコンも使って行なっていく必要がある。
これはNanoStackそのものにも言える話であって、Power-Performance Estimationはあくまで"Estimation"(推定)だから、実際にシリコンチップを製造して確かめる必要がある。今回はそうした評価を行なうためのチップの製造に成功した、という以上の話ではない。
余談だがこのチップの製造にあたってはHigh NA EUV(なのでASMLのEXE:5000シリーズを利用しているものと思われる)を必要としており、加えてLam Researchと東京エレクトロン、およびSCREENセミコンダクターソリューションズと共同で開発したとしており、実際に量産に移すにはHigh NA EUVの導入も必須となるのかもしれない。
今後のロードマップとして示されたのが下の画像だ。現在RapidusがIBMの技術を導入して2nmの生産ラインの構築に邁進しているのはご存じの通りであるが、IBMとしてはこのあと1.4nmおよび1nmのプロセスを用意しており、今回のCMOS 7A(0.7nm)はこの後に続くものになっている。それもあって、今回のCMOS 7Aに関しては「今後5年以内の生産開始を目指している」ということであった。
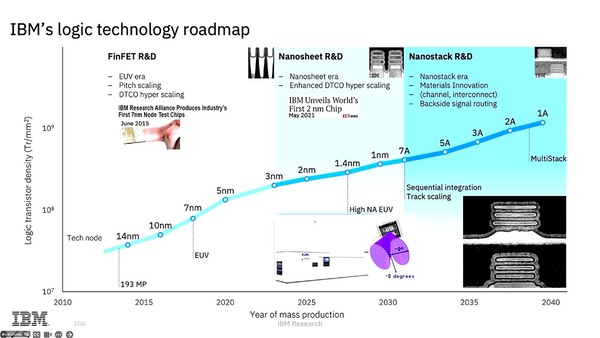
IBM的には1.4nm世代ですでにHigh NA EUVの導入が必須と判断している
問題は誰が? という話である。もともとIBMの製造設備を全部買収したGlobalFoundriesは先端プロセスの製造を断念し、それでIBMと訴訟騒ぎ(2025年1月に和解)になったのでまずあり得ない。TSMCおよびインテルはそもそもあり得ない。Samsungはひょっとすると可能性はあるかもしれないが、現在のSamsung Foundryは独自路線を貫いているので可能性は低い。
ありそうなのはRapidusになるのだが、それについては「Rapidusとは現在は2nmの量産化に注力しており、NanoStackの商用化やパートナーシップについては、今後の研究の進展に合わせて検討される予定である」という、当然の返事であった。
ただその前に1.4nmなり1nmの方がまず技術移転されそうな気はするのだが。あと0.7nm(7Å)の数字の根拠については、もうそれは実際の寸法とは無関係であるとはっきり明言された。連載837回でIMECのロードマップを示したが、ここにあるA7相当なので7Åと呼んでいる、というのが一番実情に近いのではないかと思われる。
※SRAMの説明に、一部誤解を招く記述があったため記事を修正しました。(2026年6月30日)
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 -
第873回
PC
「銅配線はまだ重要か? 答えはYesだ」 NVIDIA CEOジェンスンが語った2028年ロードマップとNVLink 8の衝撃 - この連載の一覧へ











&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")


















ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












