



ロードマップでわかる!当世プロセッサー事情 第882回
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁
2026年06月29日 12時00分更新

理論上の性能は2nmの1.5倍
しかし量産化の壁となる「ウェハ2回転送」のウルトラC工程
実際のトランジスタ構造の模式図が下の画像である。Aligned DesignのCFETの構造としては、例えば連載833回で説明したインテルのRibbonFETを積み重ねる構造がわかりやすいと思うが、PMOSとNMOSの隣接しているところからはそのまま上下に配線を引き出せないので、横ないし奥に配線を引き出す必要があり、これが結構大変である。

インテルのRibbonFETを積み重ねる構造
ところがStaggered DesignではPMOSやNMOSもそのまま配線を上下に引き出せるので、結果的に実装面積を減らせる。配線を考えなければAligned Designの方が底面積を減らせるが、配線まで加味するとStaggered Designの方がトータルで底面積を減らせるからだ。
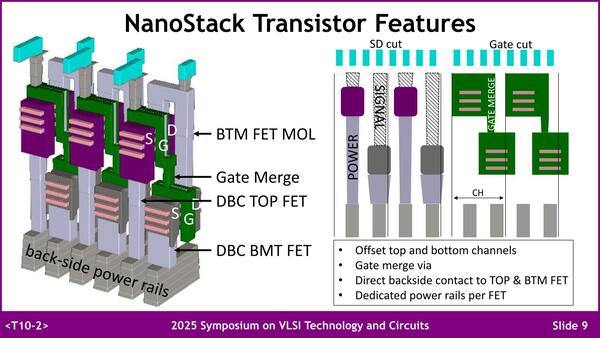
紫がPMOS、濃い灰色がNMOSのFETである
下の画像がNanoStackの性能推定である。リファレンスは2nm(現在Rapidusが製造に向けて努力中のものだ)であり、メインはAligned DesignとStaggered Designになるのだが、まずCPP(Contacted Poly Pitch)を若干なりとも減らせるうえ、Cell Heightを大幅に削減できる。要するにそれだけ高密度化できるわけだ。
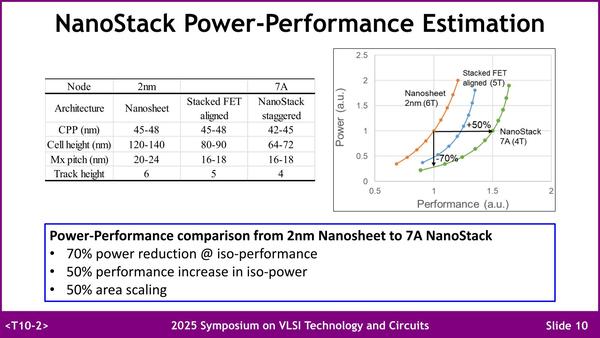
NanoStackの性能推定。セルの面積はラフに言えばCPP×Cell Heightであり、2nmの方が5400~6720nm2なのに対し、NanoStack Staggeredは2680~3240nm2となるわけで、ほぼ半減である
またNanoSheetの幅を取りやすいためか、性能も向上させやすくなっている。2nmに比較して同一消費電力なら動作周波数を50%向上、同一動作周波数なら消費電力を70%削減できる、という推定になっている。
実は今回のIBMのリリースの中に"up to 50 percent more performance, or 70 percent greater energy efficiency than IBM's 2 nm node chips"(IBMの2nmノードのチップと比較して最大50%の性能向上、または70%の性能効率改善が実現)とあるのは、上の画像の推定を基にしているわけだ。
ちなみに説明の中では、「PMOSとNMOSはそれぞれ別に製造するので、例えば異なる材料を利用して製造したり、個別に最適化を施すのも容易」とあったが、その理由が下の画像である。
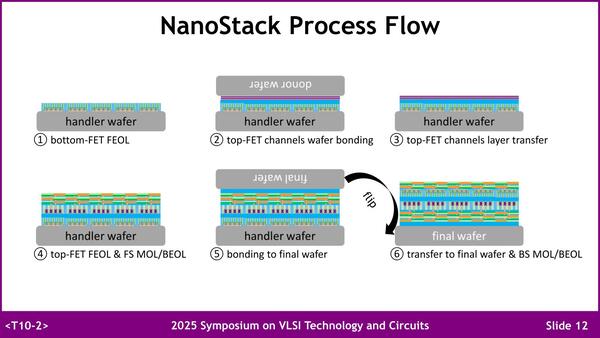
配線層も信号層と電源層で分けて構築する必要があり、おまけにLayer Transferを2回(③と⑥)行なうので、どう考えても手間が2倍以上である
順に説明すればまず①は下側のFET(IBMの場合NMOS)のGAAトランジスタ層を構築する。あくまでトランジスタ層までである(トランジスタの脇に置かれる配線はこの時点で構築されるが)。次いで、そのトランジスタ層の上にDonor Waferを張り付け(②)、次にWafer transfer(Waferを非常に薄くなるまで削り取る工程:②で張り付けたWaferは犠牲になるのでDonorと呼ばれる)を行なう(③)。
ここまですると、下側のFET層の上に新しいFETを構築するための用意ができるので、上側のFET層と、さらにその上層に構築される信号配線層を構築する(④)。次いで、Final Wafer(最終的に実装されるWafer)を上に張り付けてからひっくり返し(⑤)、今度はHandle waferと書かれているウェハーを削って、その上にBSPDN(つまりトランジスタ裏面の電源配線層)を構築する(⑥)という手順だ。
理には適っているやり方ではあるのだが、明らかにそうでなくても構築が面倒なRibbonFETベースのシリコンの製造時間が軽く倍になりそうな工程である。正確な数字は公開されていないが、ラフに言って2nm世代の2倍の工程を必要とすると思われる。当然これはウェハー加工コストにそのまま乗っかるわけで、ウェハーの製造コストが1枚10万ドルに達しても全然不思議ではないというあたりが、他社はこの方法に追従しない主な理由だろう。
PMOSとNMOSで別々の製造工程になる(し、間にシリコンの薄膜も挟まる)から、まったく異なる材料(例えば片方をIII-V族のトランジスタにすることも理論上は可能)を使うことも容易だろうが、研究室レベルではともかく量産向けとは言い難いように思える工程である。
ちなみに2025 VLSIシンポジウムでも今回の発表でも、NanoSheetの寸法などの詳細は公開されていない。ただ今回TEMを利用しての断面写真が公開されており、また事前説明会の中でSheetの厚みは約5nm、Sheet同士の間隔は約9nmと説明されている。
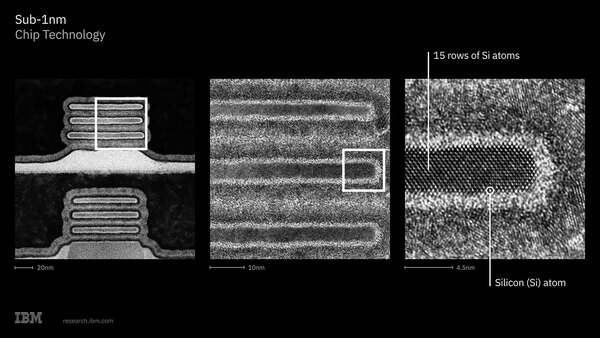
断面写真。NanoStackの正面ではなく、横から見た図になる。NanoSheetの長さは写真から推定すると80nmほどになるが、Sheetの幅は未公開
またNFETとPFETの間に配される、③でWafer Transferを行なった結果のシリコン(Si)層の厚みは25nmと説明されている。

RMGはReplacement Metal Gateの略で、NMOS FETの寄生容量を減らすことを目的にした仕組みである
※断面写真の説明に、一部誤解を招く記述があったため記事を修正しました。(2026年6月30日)
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 -
第873回
PC
「銅配線はまだ重要か? 答えはYesだ」 NVIDIA CEOジェンスンが語った2028年ロードマップとNVLink 8の衝撃 - この連載の一覧へ











&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")


















ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












