



ロードマップでわかる!当世プロセッサー事情 第876回
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解
2026年05月18日 12時00分更新

次世代の課題
3D実装「HBM4/5」への移行と設計の自動最適化
この後電源管理周りの話もあったが、本稿では割愛するとして次にパッケージングの話に移ろう。現在は2.5D、つまりSoCとシリコンインターポーザー経由で横方向に並べる形であるが、将来的にはこれを3D実装するという方向性に向かいつつあるのはご存じの通り。
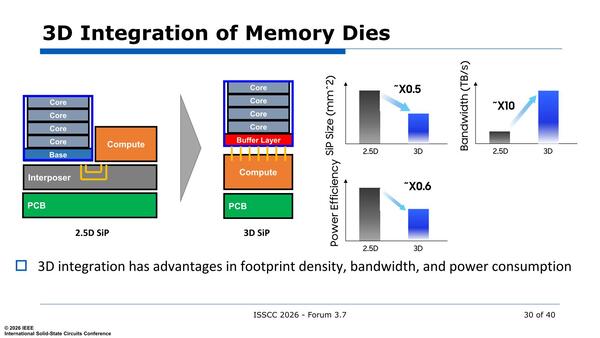
実際放熱のことを考えなければ、SoCの上に直接積層するのが一番効果的である
性能的には3D実装の方が配線距離を縮小できるし、消費電力削減にもつながる。問題は放熱であって、1つの解決策としてはHybrid Copper Bonding(Bumpを介さない、TSMCで言うところのSoIC)を利用することで熱抵抗を大幅に減らせる。
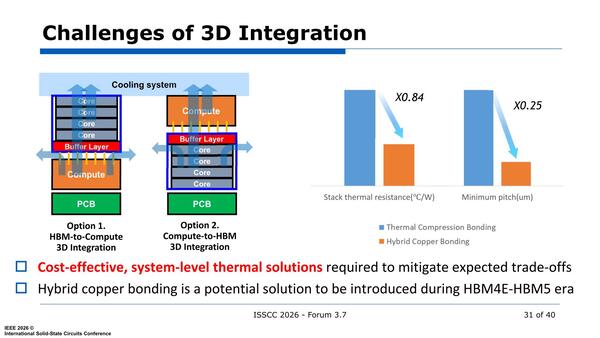
熱抵抗が減るとはいえ、1kW以上の超発熱するチップからの熱が伝わる時点で、DRAMセルの中身が全部揮発するのではないか? という素朴な疑問はいまだに解消されない。もちろん液冷前提なので十分に冷却できれば温度はそこまで上がらないのかもしれない
ところが、熱抵抗を別にしてもHybrid Copper BondingはHBM4世代で真剣に検討されている。というのは16 Hiなどの構成では、トータルの高さが高くなりすぎてしまうためだ。
高くなりすぎる理由の1つはBumpを使って積層しているためで、これをやめてHybrid BondingにすればBumpが要らない分高さが減ることになる。ただ問題はコストで、そうでなくてもHBMは高価(理由の1つはTSVを設ける必要があることである)なのに、Hybrid Bondingを使うとさらに価格が上がることになる。
ただ、HBM4e~HBM5世代ではもう本当にどうしようもなくなり、Hybrid Copper Bondingが採用される可能性はあるかもしれない。
先にも電源層を増やすという話をしたが、結果としてDRAMダイ同士やDRAMダイとロジックをつなぐμBumpや、ロジックダイとインターポーザーをつなぐC4 Bumpの数はどんどん増えているわけだが、それでも足りずにダイが燃えたりするらしい。
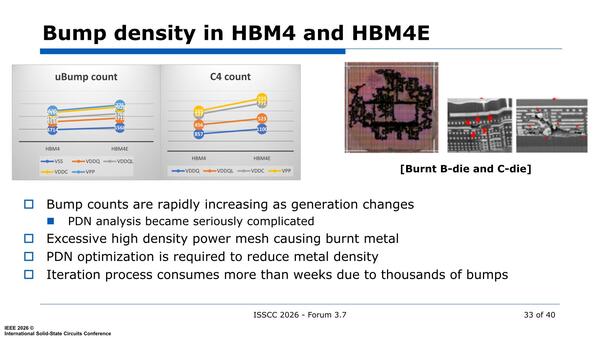
Bumpの密度が上がり、しかも消費電力が増えた結果として流れる電流が増えれば、それは燃えようというものである。なので限界を超えないように最適化することが重要、というわけだ
電源配線に関しては最適化が必要だが、これが従来は3ヵ月かかっており、これを自動配線ツールを使って2.5週に短縮するといった話が出ていた。最近はこの配線にAIを使って高速化する試みが多くなされているため、2.5週はAIをベースにしたものなのかもしれない。
実際に最適化した結果が下の画像である。配線を増やし過ぎるとコストが上がって記憶密度が減るが、減らし過ぎるとIR Dropが大きくなり、また流れる電流が増え過ぎて燃えることになる。程々のところでバランスを取るのが重要になる。
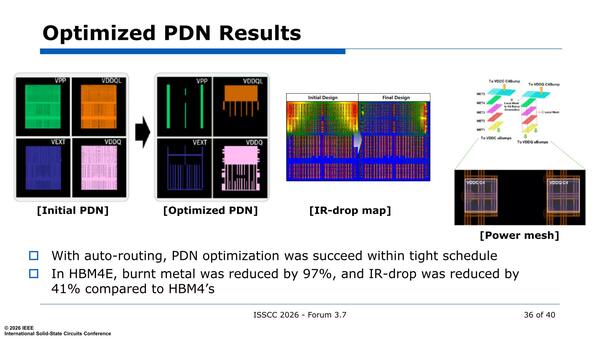
中央のIR-drop map(サーマルセンサーを使った温度分布)を見ると、温度が高い部分が大幅に減っているのがわかる
まとめとして、現状でも結構厳しいようだが、今後HBM4eやその先になると、もうHBM単体でどうにかするというよりはシリコンインターポーザーの構造を含めたトータルパッケージが必要であり、そのための協調設計が欠かせないという話であった。

ここでSamsungのHBMを使うと、そうした設計情報も一緒に提供されると宣伝しているあたりがさすがである。とはいえ、特にHBM4などは現状メーカー(SK Hynix/Samsung/Micron)の共同開発が必須で、その意味ではJEDECの標準化が成されたとは言え標準品からほど遠い状況ではある
余談だが、HBMをチップから外そう、という話はSamsungだけでなく他のメーカーも似たような話をしていた。個人的にはこれ、どっちもなし寄りのなしだと思っている。
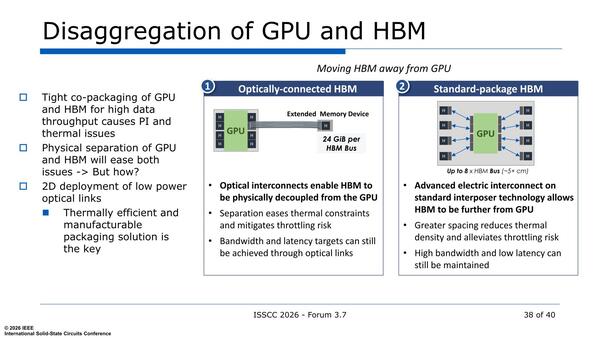
HBMをチップから外すという案は、一見賢い選択に見えるが、実際には問題多すぎである
まず1。光接続は魔法の言葉ではなく、現実問題として確かに信号のCrosstalkなどの問題は解決するが、その代わり光接続固有の問題が新たに発生する。
現状、無理なく伝送できるのは1波長あたり200Gbps(100Gbaud PAM4)であるから、HBM4の2TB/秒を実現しようとすると80波長以上必要になる。例えば16波長多重としても、片方向あたり光ファイバーが5本(つまり双方向で10本)必要になる。
それとHBM4の信号速度は8Gbpsなので、200Gbpsに変換するためのGearbox(速度を変更する機構。今回の場合8Gbpsの電気信号25本と200Gbpsの光信号を双方向変換する)が必要になるが、このGearboxの消費電力がわりとシャレにならない。つまり、光接続を使うとより消費電力が増える可能性が高い。
そして、Gearboxを介することでレイテンシーが増えるのも懸念事項だろう。2の案は、現在一番長いところでも20mm内外の配線で済んでいて、それでも消費電力などの問題が出まくっているわけで、これを50mmまで増やしたらさらにノイズが載りまくる。
おそらく信号速度をHBM2などの世代まで落とさないと実現は難しいだろう。というか1も2も、IBMがPowerで採用している。そしてIBM以外ではまったく採用されていないOMI(Open Memory Interface)を連想してしまうあたりダメだろうという気しかしないのだが、どうもこうしたHBMの分離はいまだに真剣に検討されているようだ。この方向に未来があるようには筆者には思えない。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 -
第873回
PC
「銅配線はまだ重要か? 答えはYesだ」 NVIDIA CEOジェンスンが語った2028年ロードマップとNVLink 8の衝撃 - この連載の一覧へ











&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")


















ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












