




「オープンソース原則」が派生の連鎖を生む
そして、ONOMA AIが公開時につけたレギュレーションには興味深い状況が追加されました。「収益化の禁止」という項目があるのですが、その内容は「クローズソースで微調整/マージされたモデルを収益化することは禁止」、「派生モデルやバリアントをオープンに公表しなければならない」、「このモデルはオープンソースでの使用を意図しており、すべての派生モデルも同じ原則に従わなければならない」というものです。
つまり、独自に追加学習モデルを開発した場合には、それを公開せずにビジネス化することは認めないというものでした。これがこのモデルの派生モデルが相次いで発表される呼び水となりました。
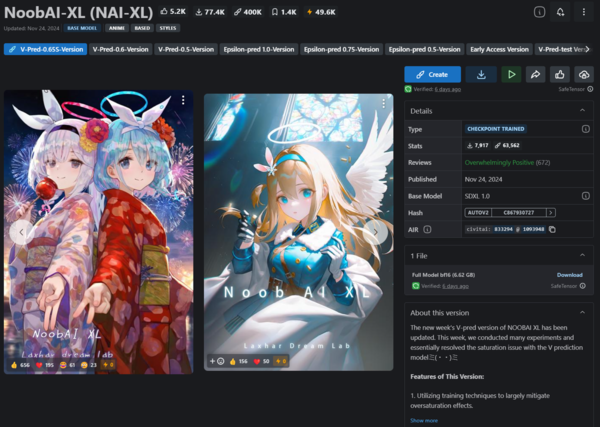
CivitAIに公開されているNoobAI-XL。最新バージョンは11月24日に公開されている
その有力な派生モデルとして登場したのがNoobAI-XLでした。11月に登場したこのモデルは、Laxhar Labというグループによって開発されていますが、中国のクラウド企業Lanyun Cloud(北京蓝耘科技股份)からの支援を受けており、最新のバージョンでは画像生成AI用のデータ配布サイトの米CivitAIとクラウドAIサービスのシンガポールSeaArt.aiも支援に参加しています。
学習データには、2024年10月にアップデートした最新のDanbooruのデータに、キュレーションサイト「e621」のデータを整理してHugging Faceで公開されている「e621-2024-webp-4Mpixel」という400万枚のデータセットで追加学習をしたと明らかにしています。追加学習に使った画像は約1000万枚に近いのではないかと推測できます。
そもそもこのモデル名のNoobAI-XLは、略すとNAI XLとなるため、本家のNAIの真似をして開発され、さらには追い抜く性能を目指して開発されたことはほぼ間違いないでしょう。初期のバージョンでは、人間が適切に描写されなかったものが、改善されたバージョンが公開されたり、その後、公式にモデル専用のControlNetを発表したりと活発にアップデートが続けられています。NoobAI-XL系は、Animagine XL系やPony系との互換性も弱いため、追加学習データの専用LoRAの開発も始まっています。
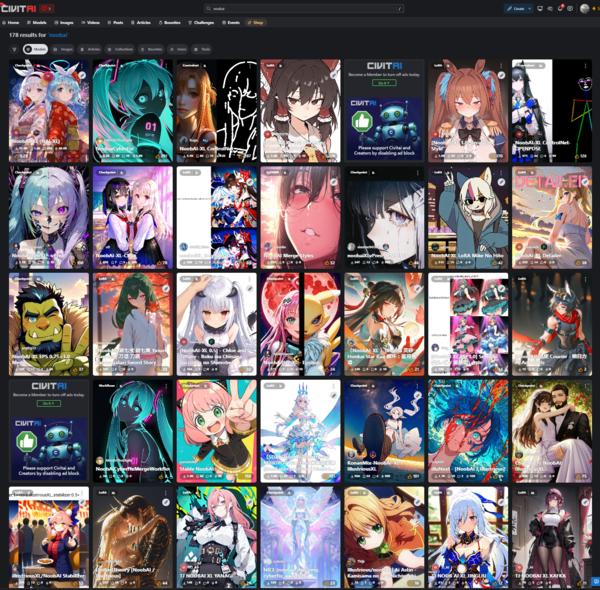
CivitAIでNoobAI-XLの派生モデルなどの公開されているデータは、公開から1ヵ月あまりで既に178種に及び、一大ジャンルになりつつある
ユーザーの派生モデルの改造もされており、意図的に「マスピ顔(プロンプトに「masterpiece」と入力した際に生成される特徴的な顔立ち)」を出すモデルや、アニメ顔をしっかりと出すモデル、また、Ilustriousなどの他のモデルとマージしてお互いの強さを補完し合うことを目指したモデルなど、様々なものが登場しています。
さらに、NoobAI-XLの規約では、ユーザーに「マージ方法、プロンプト、ワークフローなどの作業の詳細を共有する」ことが求める条項が追加されたために、派生モデルでも開発方法の詳細が明らかにされるケースが多くなり、それがさらに派生モデルの開発ノウハウの広がりを生み出しているようです。
lIlustriousやNoobAI-XLといったファインチューニングモデルの開発には、サーバーの利用コストとして数百万円程度がかかると考えられますが、ハイエンドの基盤モデルの開発には億単位の費用がかかると考えると、まだ相対的に小さな費用で開発できます。特にアニメ系モデルは、アジア圏に人気が集中するニッチニーズのモデルです。Animagine XLやPony、Kohaku XLは個人による開発ですが、企業からの支援を受けられるアジア圏のチームを中心に開発規模の拡大が進み始めているという印象です。

Noob XLはキャラクターに比べて、背景の描写力は落ちている印象がある
一方で、NoobAI-XLで画像生成をしていて戸惑うのが、アニメの特定のキャラクターに似たような画像を簡単に出力できてしまう点です。また、Danbooruに登録されている作家名でも、その人に似たような画風を再現することが容易であるようです。LoRAといったものを使わなくても、そもそものモデル自体に一定の再現力が実現されています。NovelAIで同じ現象が起きることは以前から指摘されていましたが、NoobAI-XLは学習データの規模を大きくしたことで、さらに強力になったように思えます。
ただ、背景を中心に描画能力が過去のモデルに比べて落ちているのではないかという指摘もあります。実際、背景だけ描くと、人物に比べて描画能力は落ちているように感じられます。これは元のデータが、アニメ系の女性の画像が多いため、学習に偏りが起こり、苦手な描写が新たに生まれた可能性があるとも指摘されています。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第150回
AI
無料でここまで? 動画生成AI「LTX-2.3」はWan2.2の牙城を崩すか -
第149回
AI
AIと8回話しただけで“性格が変わる” 研究が警告する「おべっかAI」の影響 -
第148回
AI
AIが15万字の小説を1週間で執筆──「Claude Opus 4.6」が示した創作の未来 -
第147回
AI
ゲーム開発開始から3年、AIは“必須”になった──Steam新作「Exelio」の舞台裏 -
第146回
AI
ローカル音楽生成AIの新定番? ACE-Step 1.5はSuno連携で化ける -
第145回
AI
ComfyUI、画像生成AI「Anima」共同開発 アニメ系モデルで“SDXL超え”狙う -
第144回
AI
わずか4秒の音声からクローン完成 音声生成AIの実力が想像以上だった -
第143回
AI
AIエージェントが書いた“異世界転生”、人間が書いた小説と見分けるのが難しいレベルに -
第142回
AI
数枚の画像とAI動画で“VTuber”ができる!? 「MotionPNG Tuber」という新発想 -
第141回
AI
AIエージェントにお金を払えば、誰でもゲームを作れてしまうという衝撃の事実 開発者の仕事はどうなる? -
第140回
AI
3Dモデル生成AIのレベルが上がった 画像→3Dキャラ→動画化が現実的に - この連載の一覧へ






































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")

















