



ロードマップでわかる!当世プロセッサー事情 第798回
日本が開発したAIプロセッサーMN-Core 2 Hot Chips 2024で注目を浴びたオモシロCPU
2024年11月18日 12時00分更新

Hot Chipsの最後の講演が、Preferred NetworksのMN-Core 2である。Preferred Networksそのものは日本の会社であり、連載670回でも触れたことがある。ASCII.jpでは同社のニュースはいろいろ掲載されているので、ご存じの方もおられるかと思う。

MN-Core 2
Preferred Networksの西川社長に牧野淳一郎教授から声がかかる
Preferred Networksは2006年創業となるPreferred Infrastructure(PFI)という企業から2014年に独立した企業である。設立当初のニュースを読むと、「IoTにフォーカスしたリアルタイム機械学習技術のビジネス活用を目的とし、自然言語処理技術、機械学習技術分野で事業を行なう」という話になっていた。ところが同社は2017年に神戸大学と共同開発体制を取り、新しいプロセッサーを開発することを決める。
もともとの動機は、理化学研究所とPreferred Networksが2016~2017年に共同で行なったNEDO(新エネルギー・産業技術総合開発機構)向けのプロジェクトである。目的は、行列演算を効率的に実行するためのプロセッサー研究で、TSMCの40nmプロセスを利用して試作した。この時理研で開発の指揮を取っていたのが牧野淳一郎教授であった。2012~2022年に理研の計算科学研究機構 粒子系シミュレータ研究チームのチームリーダーだった人物だ。
Preferred Networksの西川徹社長が、学生時代に牧野教授が手がけていたGRAPE-DRという専用計算機の開発に関わっていたということで、牧野教授から西川氏に声がかかったらしい。プロジェクトそのものは、主にAI推論向けのチップ開発を目指したわけだが、これと並行してAI学習向けのチップを開発するプランが立ち上がることになった。
2017年から牧野教授は神戸大学の大学院理学研究科教授となったことで、この学習向けのチップは神戸大学とPreferred Networksの共同開発になった。
この共同開発の結果として2020年に生まれた最初の製品がMN-Coreであり、これを利用したシステムがMN-3である。製造プロセスはTSMCの12nmで、スペックは、ピーク性能が32.8/131/524TFlops(FP64/FP32/FP16)、TDPが500Wである。

MN-Core。4つのダイを一つのパッケージに収めた構造である
同時代の製品としてはNVIDIA A100がやはり2020年5月の発売であるが、こちらはピーク性能が9.7/19.5/19.5/78TFlops(FP64/FP64 Tensor/FP32/FP16)、TDPが400Wであることを考えると、いかに性能と効率の両面でMN-Coreが高いかがわかるだろう。
先に連載670回に言及したが、MN-Coreを搭載したMN-3は、初参加となる2020年6月のGreen 500で21.108GFlops/Wを達成して見事1位に輝いている。チップ単体の性能で比較すると、FP64の場合でMN-Coreは65.6GFlops/W、A100は24.25GFlops/Wと倍以上も効率がいい。実際にはシステム全体での消費電力での比較なので、こちらで足を引っ張られている感はあるのだが。
なぜそれが可能になったか? それはMN-Coreの特異なハードウェア構造に依存する。このあたりは牧野教授の知見というか経験がものすごく色濃く反映された格好だ。MN-Coreと一般的なプロセッサーの基本的な考え方の違いが下の画像だ。
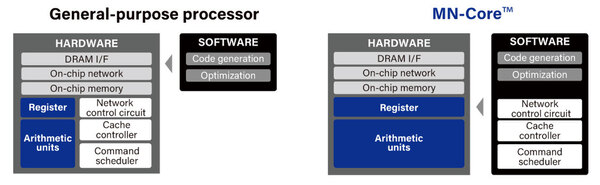
このあたりの発想は、牧野教授が開発したGRAPEシリーズのアクセラレーターとまったく一緒である
Command scheduler/Cache controller/Network controllerといった実行制御やメモリー制御、複数コアの制御などがすべてソフトウェアで実行されるようになっている。MN-Coreシリーズ(MN-CoreとMN-Core 2の両方)の説明を見ると「従来のプロセッサーとは異なり、アクセラレーター上の各processing element (以下PE)がそれぞれのプログラムカウンターや命令デコーダーを持ちません。すべてのPEは完全に同期的に動作し、ホストCPUで生成された命令列をホストから直接受け取って動作します。」とある。
要するに、連載298回で紹介したQCDSPに採用されたTI TMS320C31や、連載307回で紹介したCM-2に搭載されたWeitek WTL3132など、そういったアクセラレーターに限りなく近い。ただし単純な浮動小数点演算をターゲットにしているのではなく、行列演算をターゲットにしているのが従来との違いというあたりだろうか?
この連載の記事
-
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 - この連載の一覧へ














で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")









































