



ロードマップでわかる!当世プロセッサー事情 第796回
Metaが自社開発したAI推論用アクセラレーターMTIA v2 Hot Chips 2024で注目を浴びたオモシロCPU
2024年11月04日 12時00分更新

2週空いてしまったが再びHot Chips 2024で注目を浴びたオモシロCPUに戻る。第7弾は、MetaのMTIA v2である。初代であるMTIAは連載730回で名前だけ出てきたが、内部についての説明はしていないので、まずはここから話をしたい。
RISC-Vベースだが限りなく専用プロセッサーに近い
AI推論用アクセラレーターMTIA v1
MTIA v1は2023年に発表された。目的は推論処理の高速化であり、特に同社のサービスのRecommendation EngineをGPUベースから置き換えることを目的としていた。

MTIA v1。開発開始は2020年とのこと
製造プロセスはTSMCのN7で、800MHzで動作。INT 8で102.4TOPS、FP16で51.2TFLOPSの性能を持つとされる。
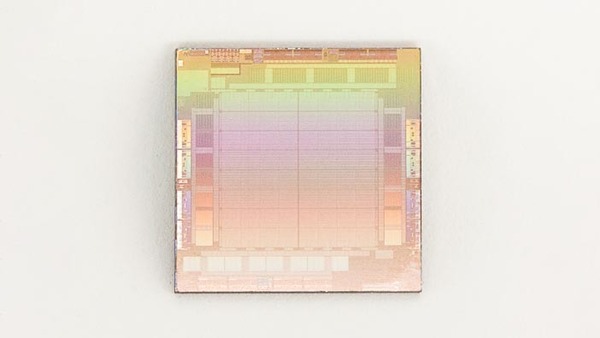
MTIAのダイ。TDPは25Wとのこと。ダイサイズやトランジスタ数は公開されていない
内部構造は下の画像のようになっており、中央に8×8で合計64個のPE(Processor Element)が配される。PEの内部構造そのものは未公開であるが、おのおののPEには2つのRISC-Vベースのコアが搭載され、片方にはVector Engineも搭載されている。
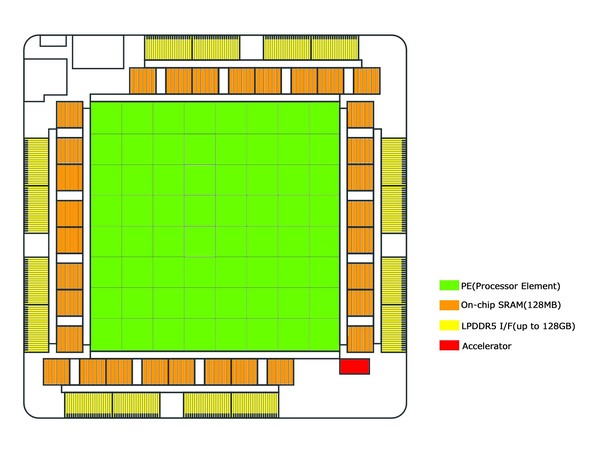
MTIAの内部構造。元の図はMeta提供。着色と脚注は筆者
また行列の乗算と加算、データ移動、非線形関数(アクティベーション用と思われる)のための専用命令が追加されているそうで、RISC-Vベースとは言え限りなく専用プロセッサーに近い。おそらくはVector Engineを搭載しているコアには行列の乗加算や非線形関数のアクセラレーターが搭載され、こちらが演算処理を行なう。
もう一方のコアはデータ移動のアクセラレーターが搭載され、これが処理の制御であったり、ほかのPEとのデータ移動だったりをつかさどるものと思われる。64PEでINT 8で102.4TOPSなので、1PEあたり1638.4GOPS。800MHz駆動だから1サイクルあたり2048 Opsという計算になる。
これをVector Engine(つまりSIMD)だけで実装しようとすると巨大なSIMD(16384bit幅!)が必要となるが、どうもこの102.4TOPSは行列乗算(俗に言うTensor Engine)の結果と思われるので、そこまで大規模な回路でなくてもなんとかなりそうだ。これに加え、各PEには128KBのSRAMが搭載されており、スクラッチパッドのように利用可能なものと思われる。
この連載の記事
-
第803回
PC
トランジスタの当面の目標は電圧を0.3V未満に抑えつつ動作効率を5倍以上に引き上げること IEDM 2024レポート -
第802回
PC
16年間に渡り不可欠な存在であったISA Bus 消え去ったI/F史 -
第801回
PC
光インターコネクトで信号伝送の高速化を狙うインテル Hot Chips 2024で注目を浴びたオモシロCPU -
第800回
PC
プロセッサーから直接イーサネット信号を出せるBroadcomのCPO Hot Chips 2024で注目を浴びたオモシロCPU -
第799回
PC
世界最速に躍り出たスパコンEl Capitanはどうやって性能を改善したのか? 周波数は変えずにあるものを落とす -
第798回
PC
日本が開発したAIプロセッサーMN-Core 2 Hot Chips 2024で注目を浴びたオモシロCPU -
第797回
PC
わずか2年で完成させた韓国FuriosaAIのAIアクセラレーターRNGD Hot Chips 2024で注目を浴びたオモシロCPU -
第795回
デジタル
AI性能を引き上げるInstinct MI325XとPensando Salina 400/Pollara 400がサーバーにインパクトをもたらす AMD CPUロードマップ -
第794回
デジタル
第5世代EPYCはMRDIMMをサポートしている? AMD CPUロードマップ -
第793回
PC
5nmの限界に早くもたどり着いてしまったWSE-3 Hot Chips 2024で注目を浴びたオモシロCPU - この連載の一覧へ
の税金、55%→20%になるか 与党が税制見直し検討も、財務省は前向きとは言えず")









測定機能を試す")


























