



単一モデルでテキスト情報と座標情報を高精度で同時抽出可能に
OCR使わずテキストと座標情報を抽出 LINE WORKSが新技術「CREPE」を発表
2024年09月27日 16時00分更新

LINE WORKSは、2024年9月25日、従来のような複数のOCRモデルを使わず、単一モデルで画像ドキュメントからテキスト情報および座標情報を同時抽出する新技術「CREPE」を開発したことを発表した。同技術に関する論文は、文書解析と認識に関する国際会議 「ICDAR2024」にて採択されている。
従来のOCRでは、さまざまなモデル(検出、認識、解析モデルなど)を組み合わせて段階処理されるため、システムの複雑度が増し、誤差が蓄積され、文書の解析精度が低下するという課題を抱えていた。CREPEでは、単一モデルで情報抽出する「End-to-Endモデル」を採用、画像全体を入力として取り込み、直接的に解析結果を生成するアプローチをとっている。
End-to-Endモデルでは、複雑なシステムが不要かつ誤差の蓄積を防ぐことができるが、“テキストの座標”を抽出できないという新たな課題が発生する。そこでLINE WORKSは、テキスト情報だけでなくその座標情報も同時に抽出することが可能なCREPEを開発。同技術は、「弱教師あり学習」という手法を採用することで、少ないデータで学習できるように設計されている。
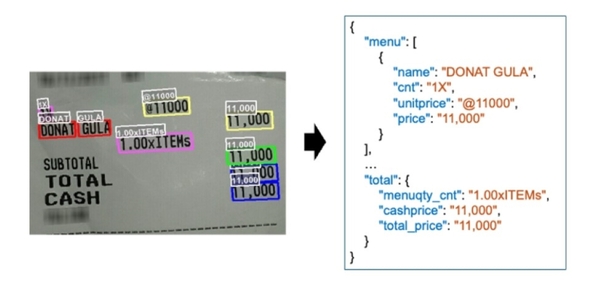
「CREPE」の画像ドキュメント解析の一例、レシート画像(左)から有用な情報を抽出した結果(右)
■「CREPE」の手法
(1)SpecialTokenを導入することでSequenceの中で、画像内のテキストを単語単位で抽出(例:
(2)Decoder最終層とLM HeadをSequenceHeadとCoordinateHeadに分離することで、テキストだけではなく座標も推論
(3)CoordinateHeadは単語の終わりを意味するトークンが出る場合にアクティベーションされるので、単語ごとの位置を獲得
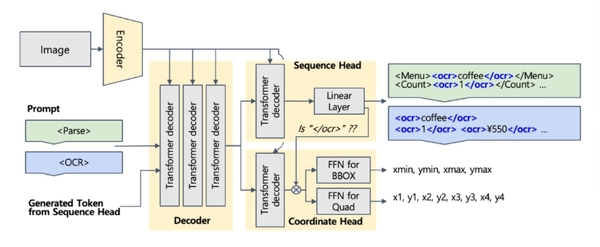
「CREPE」の概要図
LINE WORKSは、「LINE WORKS OCR(AI-OCRサービス)」にCREPEを搭載することで、さまざまなドメインに特化した高精度な解析モデルに適応できるとしている。
本記事はアフィリエイトプログラムによる収益を得ている場合があります



