



ロードマップでわかる!当世プロセッサー事情 第788回
Meteor Lakeを凌駕する性能のQualcomm「Oryon」 Hot Chips 2024で注目を浴びたオモシロCPU
2024年09月09日 12時00分更新

OryonのROBエントリー数は600以上!
インテルのSkymontに負けない規模の構成
そんなOryonだが、基本は4コア単位のクラスターでの構成になるようで、2次キャッシュは4コアで共有になる。

Oryonの基本構成。インテルのEコアのクラスターに構成的には近い
それぞれのコアの構成は下の画像のとおり。まずフロントエンドだが、8命令/サイクルのデコーダーと192KBのL1 I-Cache、強力な分岐予測と50ものRSP(Return Stack Predictor)と、インテルのSkymontに負けない規模の構成になっていることがここから大まかに見えてくる。

コアの構成。Cortex-X4は10命令/サイクルのデコード/ディスパッチ。Oryonはディスパッチが何命令/サイクルなのか未公表なのでなんとも言い難いが、ALUの数を考えればこの8命令で十分という気はする
実際の構成を見ると、ROBのエントリー数が600以上(実際は650以上)というすさまじい数になっており、一体どれだけの数の命令をインフライト状態で保持しているのか? という疑問が湧いてくる量だ。
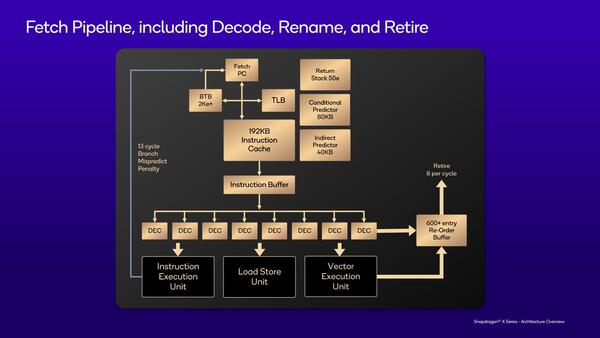
Oryonのアーキテクチャー。この図にはMicroOp Cacheが見当たらないが、省かれているのか本当にないのか、どちらだろう?
一方、バックエンドの方はALUこそ6命令/サイクルだが、分岐命令を2命令/サイクル実行でき、またレジスターファイルをALU/FPともに400以上というから、こちらも相当の命令をインフライト状態で保持できることがわかる。

SVE/SVE2をサポートしないのは意図的という気もする。AI/ML用途以外では、SVE/SVE2を使うアプリケーションはごくわずかなのを勘案してのことかもしれないし、あるいは訴訟に絡む話も関係しているのかもしれない
またFPUに関して、SVE/SVE2には未サポートであるが、NEONを最大4つ実行できるというあたりはかなり強力な構成である。もう少し詳細にみると、Integerの側は下の画像のように6つのIssue portが用意され、おのおの20エントリーのRS(Reservation Station)が付く格好だ。左の2つのユニットのみVector Unitへのリンクがあるが、これはI2V(Integer to Vector)用と思われる。
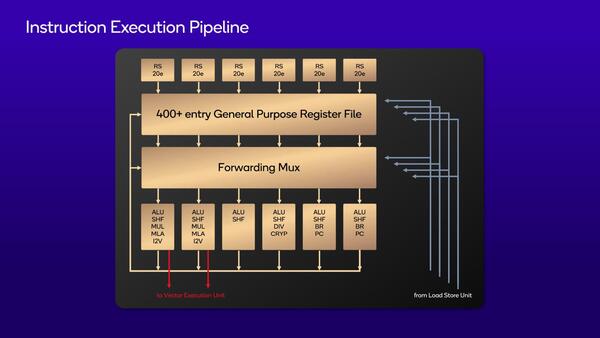
RSがIssue Port別に用意されるというスタイルはAMDのZenスタイルである
同様にFP側は、Issue Portは4つだが、おのおの128bit幅である。ほぼ対称型(FDIV/IDIV/Cryptography/V2Iのみ違っている)なので、例えばもし将来それが必要と判断されたらSVE2を実装することは可能で、ただ現状では不要と判断されたように見える。RSもおのおの48エントリーなのでかなり多い。
全体として見ると、構成そのものはそれこそSkymontやCortex-X4にはややおよばず、CrestmontやCortex-X3などに近い。ただしCrestmontやCortex-X3に比べると、インフライトの形で保持できる命令数が明らかに増えているように思える。おそらく8つのALUをそこそこの利用率で使うより、6つのALUをギリギリまで使い切る方が効率が良いと判断したのであろう。
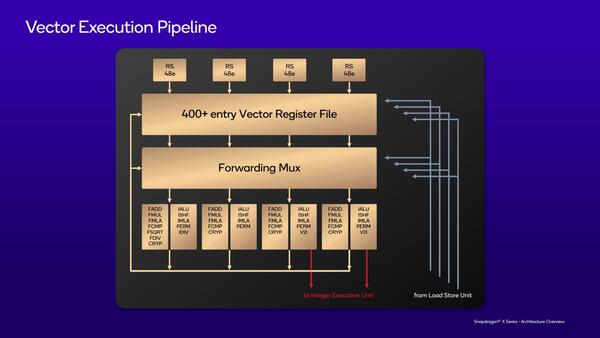
ALUに向かうのはV2I(Vector to Integer)の動作の場合のみだろう。Dividerが1個なのは、このクラスのCPUであれば妥当だ
これを支えるロード/ストアーユニットであるが、L1 D-Cacheは96KB。ロード/ストアーユニットは4基用意されている。またL1 D-TLBが224エントリーというのは、これまでのQualcommのプロセッサーと比較すると少し多いが、これはターゲットがスマートフォンからPCに変わり、より大量のデータを扱うようになることへの対策なのかもしれない。

ロード/ストアーユニット。D-TLBが7-way Associatesというのはかなり不思議。どうしてこういう選択になったのだろう?
L1はインストラクション/データともに64Bytes/サイクルの帯域になり、L1/L2も64Bytes/サイクル、L2の先は32Bytes/サイクルになっている。L2は12MBと、これもQualcommのプロセッサーとしては大容量だが、4コアで共有(つまりコアあたり3MB)と考えると妥当な線なのかもしれない。

ロード/ストアー キューの数もそれなりに多い。全体として、スマートフォン向けというよりはPC向けに近い感じである(Neoverseはさらにこのあたりが手厚いが)
メモリー管理周りは、VMを多用することを考えてか、けっこう重厚な構成である。Table Walkを同時に複数発行できる、というあたりもスマートフォン向けというよりはPC向けのCPUという感じだ。興味深いのは、メモリーアクセスのGranularityが16bitなことで、このあたりはスマートフォン向けだと感じる。

メモリー管理周りの構成。さすがに1GB Tableは未対応の模様。64bit OSに対応といっても、Oryonのターゲットはモバイルなどの省電力向けなので、そこまで重厚な対応は不要と判断したのだろう。1サイクルで仮想アドレスから物理アドレスに変換などは、PC向けはできて当然というものだが、これまでのスマートフォン向けCPUは2~3サイクルが当たり前だった
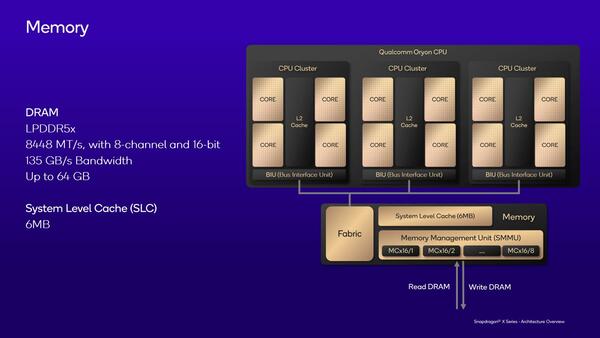
メモリーバスはトータルでは128bit幅なので、その意味ではPC向けと同じである
※お詫びと訂正:記事初出時、命令の名称に誤りがありました。記事を訂正してお詫びします。(2024年9月11日)
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























