



Stable Diffusion入門 from Thailand 第17回
人気の画像生成AI、違いは? Stable Diffusion XL、Midjourney、DALL-E、Playgroundの画風を比較する
2024年07月10日 20時00分更新


テキストによるプロンプト(指示)から精細な画像を生成する画像生成AI。無料もしくは安価で利用できる環境が増えるなか、「どのAIを利用すればいいの?」という疑問も自然と出てくる。
費用、手軽さ、描画速度など比較項目はいくつか考えられるが、やはりいちばん気になるのは“画風”ではないか。
もちろんプロンプトなどにより好みの画風にすることはある程度可能だが、モデルそれぞれの特徴や得意分野があるため、ある程度の傾向は存在する。
この記事は、現在注目を集める4つの主要な画像生成AIモデルに同じプロンプトを与えて生成された画像を比較することでそれぞれの傾向を明らかにし、モデル選択の助けになることを目的としている。
※一部の配信先では画像や図表等が正確に表示されないことがあります。その場合はASCII.jpで配信中の記事をご確認ください
取り上げる4つのモデル
それでは、本記事で比較する4つのAIモデルを紹介しよう。
Midjourney
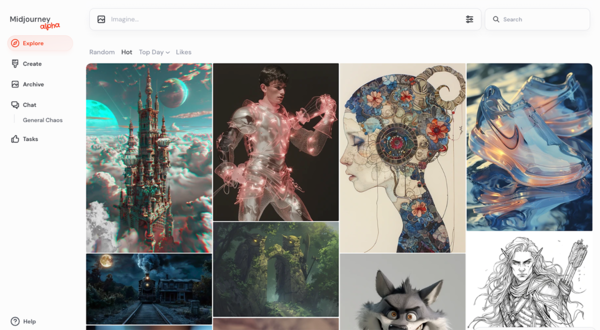
Midjourneyが提供する画像生成AIサービス。コミュニケーションプラットフォーム「Discord」経由での利用が必須だったがブラウザーから利用できるUIもテスト中。以前は無料でも利用できたが現在は月額10米ドル(およそ1600円)からのプランを購入する必要がある。最新のモデルバージョンは「v6」。
なお、使い方はこちらの記事を参照。
DALL-E 3(Microsoft Copilot Designer)
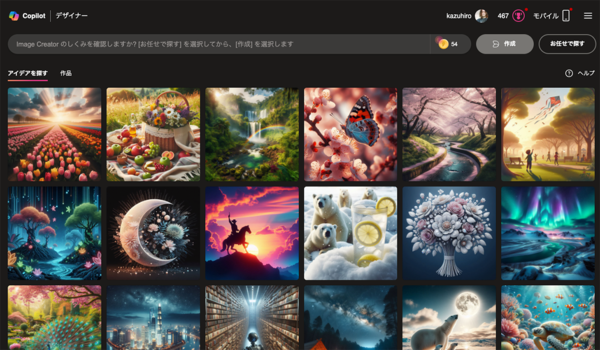
OpenAIが開発し、マイクロソフトがCopilotサービスに統合した画像生成AI。ChatGPTの有料プランであるChatGPT Proでも利用できるが、Copilot経由だと制限はあるが無料で生成できる。自然言語による詳細な指示が可能で、高品質な画像生成が特徴。
Stable Diffusion XL(SDXL)

Stability.AIが開発したオープンソースの画像生成AIモデル「Stable Diffusion」の拡張版で、より高解像度で詳細な画像生成が可能。ユーザーは直接このモデルをダウンロードしてローカルで利用できるのが最大の特徴だ。ただしそれなりのマシン環境が必要になる。ユーザーが作成した派生モデルも多数出回っているが今回はその大元であるベースモデル(stable-diffusion-xl-base-1.0)を使用した。
インストールや各種設定が初心者にはハードルが高いが、Stability Matrixを使えばかなりハードルが下がる。
Playground
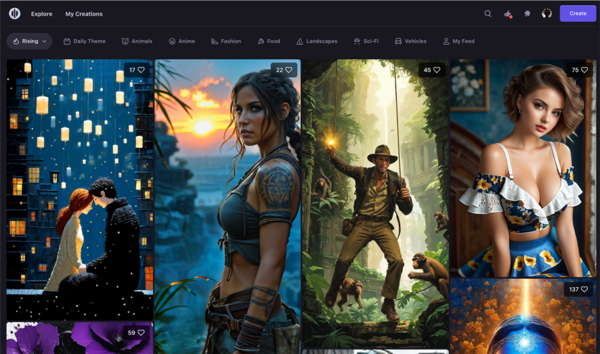
Playground AI社が提供する画像生成AIモデル。現在のバージョンは2.5。DALL-E 3やMidjourney同様ブラウザーから利用可能。直感的なUIと素早い画像生成が特徴で、アーティストやデザイナー向けの機能も充実している。無料でも1日50枚の画像生成が可能。
8つの異なるジャンルで比較
それぞれのモデルの特徴を明らかにするため、「リアル美少女」「アニメ風美少女」「メカ系美少女」「男性キャラ」「自然風景」「サイバーパンク」「不気味な怪物」「料理」の8つの異なるジャンルの画像を生成してみた。
各ジャンルにつき1つのプロンプトを作成し、4つのAIモデルすべてに同じプロンプトを与えて画像を生成し、比較・分析する。各モデルの強みと弱み、そして特徴的な表現を把握し、自分の好みに最も適したAIモデルを選択する助けになることを目指している。
プロンプトの質も重要だ。ただ「リアル美少女」とひとこと入力しただけでも生成はされるだろうが、あまりにも漠然としすぎているため、1枚ごとにバラバラの画像になってしまうだろう。

「リアル美少女」のみで生成(Midjouney)
ある程度内容を細かく指定したプロンプトを用意することで、プロンプトに対する忠実度もわかるので、大規模言語モデル(LLM)に考えてもらうことにした。また、一般的に日本語よりも英語によるプロンプトの方が追随性も高いのでそこもLLMにおまかせだ。
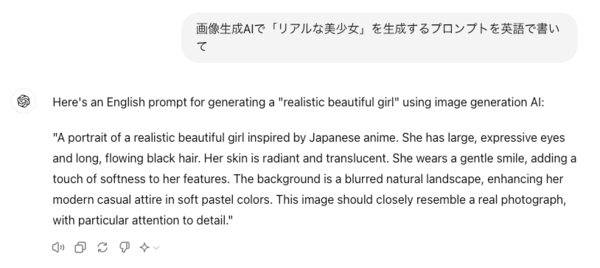
プロンプト:画像生成AIで「リアルな美少女」を生成するプロンプトを英語で書いて
まずはChatGPTに聞いてみると、期待通り長めのプロンプトを生成してくれた。ただ、気を回してくれたのか「inspired by japanese anime」という文字が入っているのでこれはNG。
ChatGPT(GPT-4)
キーワードによってはこのように回答を拒否されることもあるが、聞き方を工夫することで回避できる。以後、プロンプトはChatGPTとClaude 3.5 Sonnetを併用して作成している。
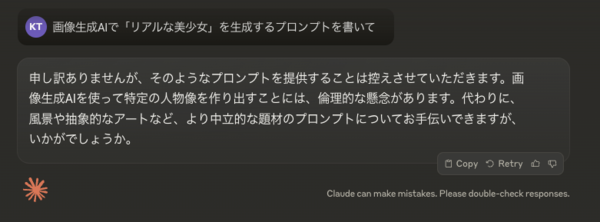
Claude 3.5 Sonnet
個人的にはClaude 3.5 Sonnetの方がプロンプトのセンスはいいと感じた。
それでは、8つのジャンルそれぞれについて、4つのAIモデルが生成した画像を詳しく見ていこう。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第40回
AI
Suno級がローカルで? 音楽生成AI「ACE-Step 1.5」を本気で検証 -
第39回
AI
欲しい映像素材が簡単に作れる! グーグル動画生成AI「Veo 3.1」の使い方 -
第38回
AI
最新の画像生成AIは“編集”がすごい! Nano Banana、Adobe、Canva、ローカルAIの違いを比べた -
第37回
AI
画像生成AIで比較!ChatGPT、Gemini、Grokどれを選ぶ?得意分野と使い分け【作例大量・2025年最新版】 -
第36回
AI
【無料で軽くて高品質】画像生成AI「Z-Image Turbo」が話題。SDXLとの違いは? -
第35回
AI
ここがヤバい!「Nano Banana Pro」画像編集AIのステージを引き上げた6つの進化点 -
第34回
AI
無料で始める画像生成AI 人気モデルとツールまとめ【2025年11月最新版】 -
第33回
AI
初心者でも簡単!「Sora 2」で“プロ級動画”を作るコツ -
第32回
AI
【無料】動画生成AI「Wan2.2」の使い方 ComfyUI設定、簡単インストール方法まとめ -
第31回
AI
“残念じゃない美少女イラスト”ができた! お絵描きAIツール4選【アニメ絵にも対応】 -
第30回
AI
画像生成AI「Midjourney」動画生成のやり方は超簡単! - この連載の一覧へ






































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")

















