




402ページのテキストを読み込んで回答する
では、いくつかデモを見ていこう。
この動画では、Gemini 1.5 Proにアポロ11号の月へのミッションについての動画の402ページ(およそ32万トークン)に及ぶ文字起こしデータ(PDF)を読み込ませた上で「Find 3 comedic moments. List quotes from this transcript and emoji.(動画内の3つのおもしろシーンを絵文字付きで引用して)」という難易度の高そうな質問をしている。
すると、ものの30秒程度で3つの笑えるシーンの引用および、その文脈を回答している。
さらに、「人類の最初の一歩」を描いたイラストを読み込ませたところ、15秒ほどでそのシーンをタイムコードで特定している。
44分の映画から特定のシーンを検出
この動画では、44分(およそ70万トークン)のバスター・キートンの無声映画を読み込ませ、「Find the moment when a piece of paper is removed from the person's pocket and tell me some key information on it, with the timecode.(誰かのポケットから紙片が取り出される瞬間を見つけて、その上に書かれた重要な情報と、タイムコードを教えてください)」という質問をしている。
さすがに動画からの検索は時間がかかるのか1分近くかかったが、ばっちり正解している。
さらに、映画内の特定のシーンを雑に描いたイラストを読み込ませ、そのシーンを正確に特定し、タイムコードで回答するといった芸当も余裕でやってのけている。
長大なコード群から横断検索
この動画では。100,000行(およそ82万トークン)を超えるJavaScriptのサンプルコード集を読み込ませ、その中から目的のサンプルを見つけ出し、役立つ修正を提案し、コードの異なる部分がどのように機能するかについて説明するというタスクをこなしている。
プロンプトから勝手に学習
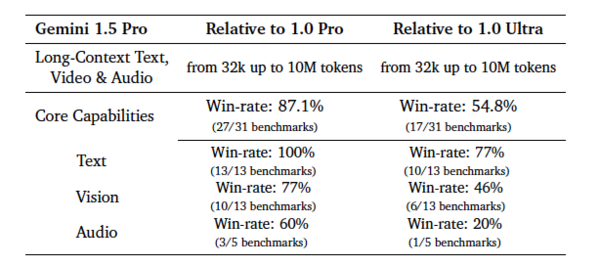
Gemini 1.5 Proは、ベンチマークの87%で1.0 Proを上回り、1.0 Ultraとほぼ同様(テキストは1.5Proの方が、逆に音声は1.0 Ultraの方が得意)の性能を発揮している。
また、最大100万トークンの意図的に長いテキスト内から特定の小さなテキストを見つけ出す「Needle In A Haystack(針を藁の山から見つける)」テストでも、Gemini 1.5 Proは99%の確率でその部分を見つけ出したという。
さらに、世界中で200人未満の話者しかいないカラマン語の文法マニュアルを読み込ませると、同じマニュアルから学んだ人間と同レベルの翻訳スキルを身につけたという。これは、追加のファインチューニングをしなくても、長いプロンプトで与えられた情報からAIが能動的に新しいスキルを学ぶ「コンテキスト内学習」と呼ばれる現象だ。
100万トークン版の公開も期待できる?
Gemini 1.5 Proはこれまでのモデル同様、グーグルのAI原則と安全ポリシーに沿って、広範な倫理と安全性のテストを受けることになる。
その後も、これらの研究学習をガバナンスプロセス、モデル開発、評価に統合し、AIシステムを継続的に改善していくとしている。
グーグルおよびアルファベットCEOのサンダー・ピチャイ氏は「長いコンテクストウィンドウは全く新しい機能を可能にし、より有用なモデルやアプリケーションを構築するのに役立ちます。この実験的な機能の限定プレビューを、開発者と企業顧客に提供できることを嬉しく思います。」と語っている。
また、Google DeepMindのデミス・ハサビスCEOは「完全な100万トークンのコンテキストウィンドウを展開するにあたり、私たちはレイテンシーを改善し、計算要件を減らし、ユーザーエクスペリエンスを高めるための最適化に積極的に取り組んでいます。」と語っている。
100万トークンのコンテキストウィンドウを持ったバージョンの公開も想定よりずっと近いのかもしれない。
本記事はアフィリエイトプログラムによる収益を得ている場合があります















の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")



























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





