





Stability AIは11月13日、商用利用可能な日本語画像言語モデル「Japanese Stable VLM」をリリースした
画像の内容を日本語で説明
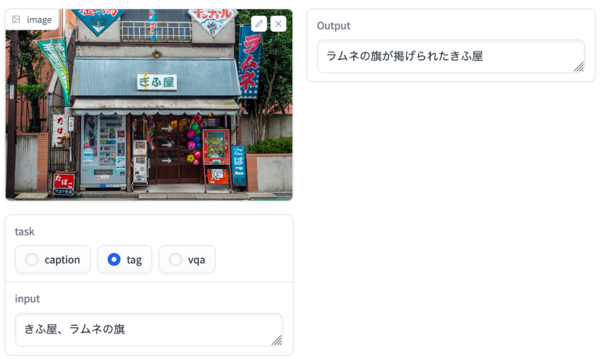
「Japanese Stable VLM」は、日本語で利用できる画像言語モデル(Vision-Language Model:VLM)。入力した画像に対して文字で説明を生成できる「画像キャプショニング」機能のほか、あらかじめ出力キャプションで使ってほしい単語を入力できる「タグ条件付きキャプショニング」機能も用意されている。
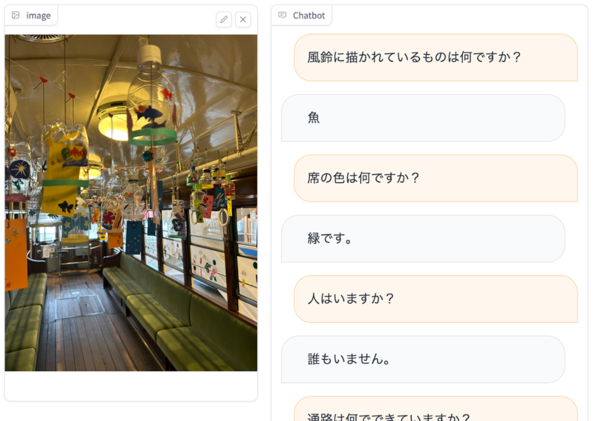
さらに、上記画像のように、画像についてのユーザーの質問に回答したり、動画のフレームを抜き取ることで、動画キャプショニングやリアルタイム動画の質問応答も可能としている。
商用利用も可能
訓練には最新手法「LLaVA-1.5」のモデル構造・学習手法を適用、言語モデルには同社が10月25日に発表した「Japanese Stable LM Instruct Gamma 7B」を用い、画像エンコーダとしてOpenAIの「clip-vit-large-patch14」を使用している。
クリエイターからオプトアウトの要求があったり、robot.txtや利用規約で利用が禁止されているデータは訓練には使用していないという。
なお、2023年8月17日に発表された最初のバージョン「Japanese InstructBLIP Alpha」は非商用利用に限定されていたが、今回のモデルは商用利用可能になっている。
ただしライセンスは「STABILITY AI JAPANESE STABLE VLM COMMUNITY LICENSE」とだけ記されており、詳細は準備中のようだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")

















