




アダプティブGPUアロケーター技術
富士通は11月9日、CPUとGPUの計算処理をリアルタイムに切り替える世界初の技術を開発したと発表した。
高精度なシミュレーションやAI予測を活用する研究開発においてはスーパーコンピューターやGPUといった高性能な計算機が利用されているが、複数のユーザーが計算機を共有利用しているため、プログラム処理中に別のプログラムを処理するとメモリー不足によるエラーや複数計算機間の同期タイミングのずれによる計算速度の大幅な低下を招いていた。
プログラムごとに計算リソースを割り当てプログラム終了後に次のプログラムを処理することから、リアルタイム性が求められるデジタルツインや生成AIへの活用が困難という問題があった。とくに深層学習などでGPUの需要が高まったことからGPUで処理した方が高速化するプログラムがあるにもかかわらず、GPU利用がプログラムの一部のみに留まるなど、低効率な利用が存在する点も課題だったという。
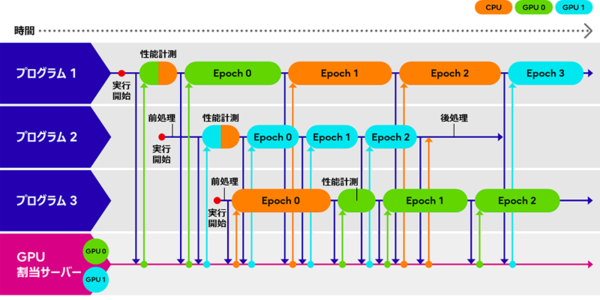
今回開発した「アダプティブGPUアロケーター」技術は、複数のプログラム処理を実行中の場合においても、GPUを必要とするプログラム/CPUで処理しても良いプログラムの高速化率を予測して区別。優先度の高いプログラム処理に対してリアルタイムにGPUを割り振ることができる。
これにより、GPUを利用するAIや高度な画像認識などのアプリケーション開発において、グラフAIデータを処理するモデルの学習などを素早く実施することが可能になるという。
インタラクティブHPC技術(CPUとGPUの割り当て切り替えのイメージ)
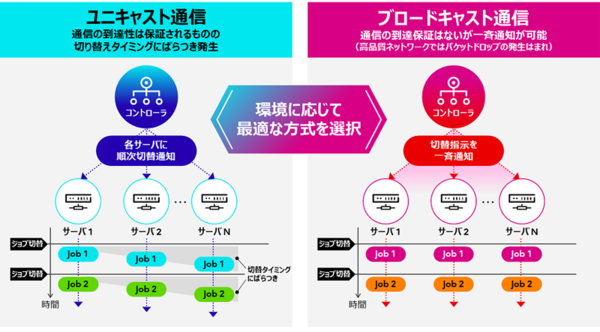
さらに、複数台のコンピューターを協調動作させるHPCシステムにおいて、現在実行中のプログラムの完了を待たずに利用可能とする技術を開発。従来の制御方式は各サーバーにプログラム実行を切り替える際にユニキャスト通信を利用しているため切り替えタイミングのばらつきが発生し、リアルタイムでのプログラム実行の一括切り替えが困難だった。今回、プログラム実行を切り替える通信に一斉送信可能なブロードキャスト通信を採用し、従来はプログラムの実行切り替え間隔は秒単位であったところを256ノードのHPC環境において100ミリ秒へと短縮。
同社では今後、アダプティブGPUアロケーター技術については、先端AI技術を素早く試せる「Fujitsu Kozuchi (code name) - Fujitsu AI Platform」におけるGPUが必要な処理において活用するとしている。また、インタラクティブHPC技術については、同社の40量子ビットの量子コンピュータシミュレーターにおいて、多数のノードを用いて協調計算する部分へ適用予定としている。
本記事はアフィリエイトプログラムによる収益を得ている場合があります





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")

















