



ロードマップでわかる!当世プロセッサー事情 第736回
第6世代XeonのGranite Rapidsでは大容量L3を搭載しMCR-DIMMにも対応 インテル CPUロードマップ
2023年09月11日 12時00分更新

Granite Rapidsではコアあたり4MBの
大容量3次キャッシュを搭載
先ほど次々世代XeonとしてSierra ForestとGranite Rapidsの名前を挙げたが、それを明確にしたのが下の画像だ。

画像中央やや左に、Sierra ForestとGranite Rapidsと明記してある。右下の図にあるL2/L3の容量はPコアの場合なので、Eコアの場合はまた異なると思われる
構造的にはSapphire Rapidsとよく似ており、縦横のメッシュの交点にCPUコア+2次キャッシュ、それとLLC(3次キャッシュ)とSF(Snoop Filter)とそれを接続するCHA(Caching and Home Agent)から構成される。
コアあたり4MBというのはかなりのサイズで、例えば60コアのSapphire Rapidsがコアあたり1.875MBとずいぶん刻んできたのに対し、猛烈な大盤振る舞いと言えなくもない。2次キャシュの2MB/コアはSapphire Rapidsと変わらないが、これで3次キャッシュより2次キャッシュの方が大きいという逆転現象から解放された格好である。
この大容量3次キャッシュを搭載した理由は2つあると思われる。1つはMilanやGenoaなど、EPYCへの対抗である。EPYCは4MB/コアの3次キャッシュを搭載しており、さらに3D V-Cache搭載のMilan-XやGenoa-Xは12MB/コア相当の容量となる(いくつかのSKUでは3次キャッシュを有効にしたままコアを無効にすることで、24MB/コアの容量が実現している)。
なんでもかんでも大容量3次キャッシュの効果があるわけではないという話は連載725回のGenoa-Xの折にしているが、逆に言えば確実に効果がある用途も存在する(特にHPCなどでこれが顕著である)ことを考えると、Milan-XやGenoa-Xにはおよばないにしても、Milan/Genoa同様に4MB/コアを実現したいというニーズは高かったのだろう。
大容量3次キャッシュを搭載したもう1つの理由は「それが可能になったから」である。プロセスの微細化もあり、同じ面積であればSapphire Rapidsより多いコア数を搭載できるし、コア数が変わらなければより大容量の3次キャッシュを搭載できる。
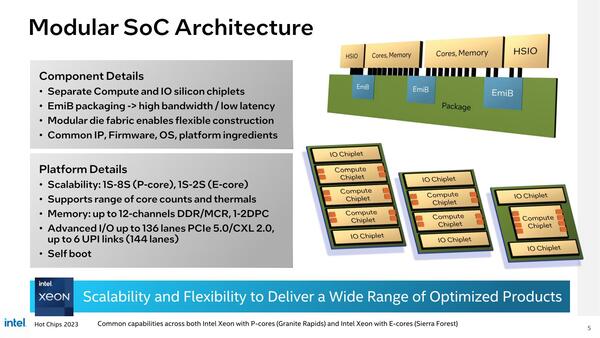
Granite Rapidsは最大12chのDDR/MCR-DIMMを装着できる
前のページで掲載した画像に戻るが、Granite Rapidsは最大12chのDDR/MCR-DIMMを装着できるとしている。その脇の図を見ると、コンピュート・チップレットあたり4chのDDR/MCR-DIMMが出ていると想像できる。ここから、コンピュート・チップレットそのものは最大3つの構成と予想できる。
コア数はまだ未公開だが、最大132コア構成という話が伝わってきており、つまりコンピュートタイルあたり44コア構成になる。かなり大きいチップレットに見えるかもしれないが、そうでもない。Sapphire Rapidsの内部構造は連載702回で説明したが、ダイの構成写真から見ると、Sapphire Rapidsに入っていたPCIeやCXL、UPIのブロックはGranite Rapidsでは不要である。

Sapphire Rapidsのダイ
したがって、同じダイサイズでもコアが19個は確保できる。上の写真では5×4で20個のブロックだったが、一段増やして6×4にすればコアが23個+DDR5×2ch。それを2つ横に並べれば、コア46個+DDR5×4chの計算になる。
こんなに大きなコアでは800mm2に達するわけだが、それはIntel 7を使った場合であって、Intel 3を使えば計算上は600mm2程度に収まる計算だ。実際には3次キャッシュが増える分、ブロックのサイズはもう少し大きくなるだろうが、700mm2程度には収まると見られる。
これは従来のSapphire Rapidsのソケット(LGA4677)には入りきらないかもしれないが、Granite Rapids世代では一回りから二回り大きいLGA7529が使われると伝えられており、これなら問題ないだろう。
ここでコンピュート・チップレットあたり22コアくらいに収めて、その分チップレットの数を6個に増やす(あるいはチップレットあたり11コアで12チップレットだろうか)というのがAMDの流儀であるが、インテルは露光できる限界にチャレンジするのが流儀らしいので、おそらくこんな構成になるものと思われる。
ちなみにSierra Forestも仕組みとしては同じであり、こちらは最大144コアなので、チップレットあたり48コアとなる計算だ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























