



Stable Diffusion入門 from Thailand 第3回
画像生成AI「Stable Diffusion XL(SDXL)」の使い方 初めてなら「Fooocus」がオススメです
2023年09月14日 09時00分更新


複雑化するStable Diffusion界隈
前回からずいぶん間が空いてしまったが、ようやく第3回である。

届いたパソコンに「Python」、「Git」、動作環境「WebUI(A1111版、以下「WebUI」と略記)」をインストールして、1枚目の画像を生成したところで前回は終わってしまったのだが、もちろんその後なにもせずに1ヵ月が過ぎてしまったわけではない。
実はこの後、プロンプトの研究、各種パラメーターの把握、モデルとVAE(オートエンコーダーの一種)の探求、様々なExtension(拡張機能)の導入、Custom Script、LoRA、ControlNet、LyCORISなどなど様々なことを調べ、試してはいたのだが……。
とにかく調べなきゃいけないことが多すぎる!!!
そもそもStable Diffusion自体が登場から1年もたっていないうえに、オープンソースで公開されているため、世界中の猛者たちが試行錯誤しながら毎日新たなテクニックを考案したり、新たなツールやモデルを開発・公開している世界だ。
それゆえ定番的なテクニックすらすぐに時代遅れになってしまい、毎日の情報キャッチアップが必要になってくる。
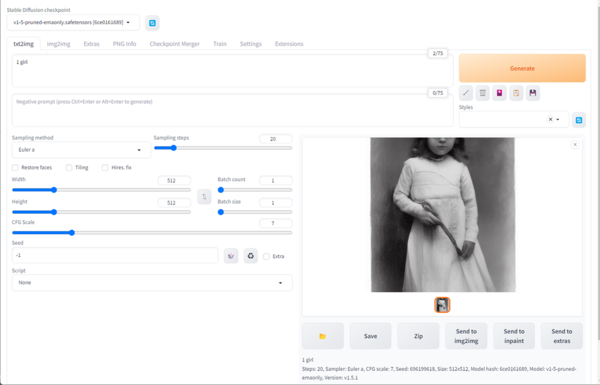
インストール直後の筆者環境
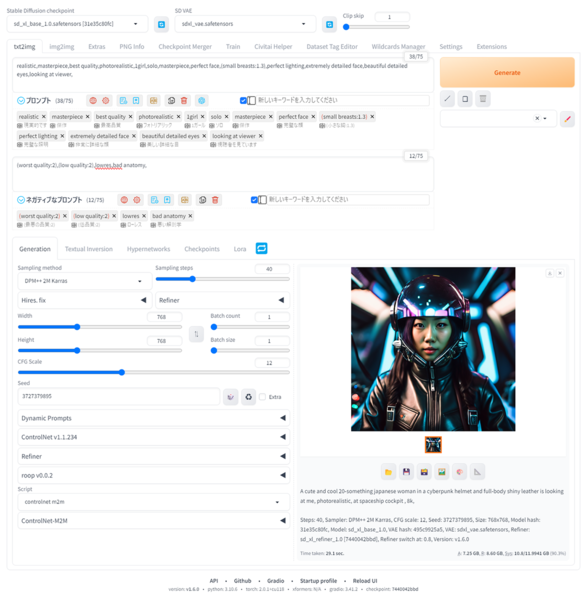
現在の筆者環境
Web UI自体も頻繁にアップデートを重ねている上に、派生モデルやLoRA、別の人が開発したExtensionなどを導入していった結果、インストール時点から比べ物にならないほどUIも複雑化してしまった。
そしてとどめとなったのが7月27日に登場したStable Diffusionの最新バージョンとなる「Stable Diffusion XL 1.0(SDXL 1.0)」だ。
参考:最新の画像生成AI「SDXL 1.0」実写系イラストのクオリティがすごい!!
SDXL以前は「Stable Diffusion v1.5(SD v1.5)」が主流となっており、多くの派生モデルや拡張機能が開発されていたのだが、SDXLは以前のバージョンとかなり異なっている。

SDXLモデルの概念図
特に「Base」と「Refiner」という2つのモデルを組み合わせて使う必要があるため、当初「Stable Diffusion Web UI」では、少し面倒な手順を踏む必要(現在は対応済み)があった。
また、画像をある程度コントロールできる「LoRA」の多くは、SD v1.5用でSDXLには対応していないなど、互換性に問題がある。
以上のようなこともあり「さて、どこから説明していけばいいのやら……。」と悩んでしまっていたというのが更新が遅れた理由だ。
(いまごろ始めた『サイバーパンク2077』に時間を吸い取られてしまったことは別として)
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第41回
AI
グーグル画像生成AI「Nano Banana 2」が変えた3つのポイント -
第40回
AI
Suno級がローカルで? 音楽生成AI「ACE-Step 1.5」を本気で検証 -
第39回
AI
欲しい映像素材が簡単に作れる! グーグル動画生成AI「Veo 3.1」の使い方 -
第38回
AI
最新の画像生成AIは“編集”がすごい! Nano Banana、Adobe、Canva、ローカルAIの違いを比べた -
第37回
AI
画像生成AIで比較!ChatGPT、Gemini、Grokどれを選ぶ?得意分野と使い分け【作例大量・2025年最新版】 -
第36回
AI
【無料で軽くて高品質】画像生成AI「Z-Image Turbo」が話題。SDXLとの違いは? -
第35回
AI
ここがヤバい!「Nano Banana Pro」画像編集AIのステージを引き上げた6つの進化点 -
第34回
AI
無料で始める画像生成AI 人気モデルとツールまとめ【2025年11月最新版】 -
第33回
AI
初心者でも簡単!「Sora 2」で“プロ級動画”を作るコツ -
第32回
AI
【無料】動画生成AI「Wan2.2」の使い方 ComfyUI設定、簡単インストール方法まとめ -
第31回
AI
“残念じゃない美少女イラスト”ができた! お絵描きAIツール4選【アニメ絵にも対応】 - この連載の一覧へ














&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")

















ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")
